

“The year of automation is here!”
“Don’t let your team manually do what should be automated.”
“The one who still manages bids manually in Google Ads is wasting her time.”
These and other like-minded sentiments are being uttered by PPCers who just a couple of short years ago were (rightfully) hesitant about incorporating too much automation into their systems.
What happened?
Well, that’s for a different article.
Call it, evolution of the system, evolution of our thinking, or most likely a mixture of both… but the world of PPC has certainly joined the lane of no return on the road to automation.
The Winds of Change & Automation
In my paid search agency, ZATO, we do a bit of work with automated systems in Google Ads both in moderated, human-controlled fashion as well as in near fully-automated systems such as Google’s Smart Shopping Campaigns released late 2018.
I have engaged in debates on Smart Shopping data and automation (link below) and written many articles on the topic of Smart Shopping.
I am especially interested in Smart Shopping automation because I believe it is the first wave of “the new Google Ads”.
That is, Google wants to utilize more automated systems such as audiences or product feeds to allow them to control more of the placement and bidding of ads than the old school method of keyword targeting.
In this regard, I think there are crucial aspects to automation, that the PPC industry (and in many ways, the broader digital marketing industry) needs to sit up and take notice… before we are too far down the path of obscure data.
Based on this, I want to dig into four crucial and somewhat contradictory elements of automation that our industry needs to be aware of, talk about, research, and determine the best route forward.
Why Is This a Crucial Conversation Right Now?
It is a crucial conversation to have now because the platforms want to “obfuscate” (Google’s word) the data because it is in their favor to run everything. The argument goes, obfuscated data will make for better machines.
But shouldn’t we pump the brakes a bit and consider this?
I am certainly no Luddite, but the speed with which we are launching into fully automated systems in PPC suggests that we need to slow down to contemplate a few things.
I think the time for contemplation, is now or never.
That is, if we don’t discuss this and help our industry develop strong, guiding convictions on the various aspects and nature of data and automation, then we are giving the Platforms free rein to do as they please.
In this regard, they have already communicated (quite clearly) through public statements and private conversations that their desire is to:
- Control every aspect of the automated process.
- Keep that data hidden to prevent outside influence on the algorithm.
I think this is problematic for a variety of reasons, as I have written elsewhere.
My hope is conversations like this will help automation continue to develop and do great things while maintaining adequate human oversight and process transparency.
The purpose of this post is not to reconcile differences, but reveal difficulties (even contradictions) and encourage conversation. The conversation is the win here.
If you disagree with something I say next, great! Talk about it, write about it.
Rather than allow the platforms (with the most to gain) to completely shape the automation process and conversation, let’s discuss the following elements of automation (and more!) and help move our industry forward.
Two Sets of Necessary, but Contradictory Elements of Automation
Opinion A: The Data Is Owned by the One Paying for It (The Advertiser)
The first necessary element of automation I believe is crucial here is that the one paying for the data owns it.
In this regard, I do not see the advertiser as renting the data from the platforms, but as purchasing it.
At least, that’s what I believe should be happening here, regardless of what the platforms claim. Whatever the opinion, this is surely to be a core argument in the coming days of automation.
Who actually owns the data?
The one who owns the data is the one with the rights. The rights for which data they want to see, how they want to use it, etc.
Of course, even data usage is getting complicated with privacy concerns, FTC (or EU) involvement, and the like. Many, many more articles will be undoubtedly written on this in the days to come.
Overall though, if data is owned by the advertiser, then the logic is that the advertiser (or the one paying for the data, in reality) has some right to the data – at the very least the data that is “necessary” for the advertiser/company in usage.
In terms of necessary data being shown to the advertiser paying for it, this notion is actually championed by Google themselves in regard to a third-party advertiser being required to give certain data to the account owner because “they need to have the right information to make informed decisions.”
I agree whole-heartedly!
The Problem With Opinion A: Not All Data Is Actionable or Helpful
Here’s the problem with the above, and thus why it is seemingly contradictory, and messy…
What data do you have a right to as the one paying for it? All of it everywhere?
Okay, go buy a server farm for the mounds of junk data that you can’t do anything with. The loads of this, that and the other data points you’ll never, ever, ever use.
Unlike the belief of “big data”, the one with the most data doesn’t win anything. It’s the one who can use that data correctly who will win.
Google calls this necessary data the “right information” for making informed decisions… but that’s complex as well.
One advertiser thinks Average Position was crucial for making informed decisions, while another thinks it wasn’t necessary and doesn’t really miss it. Who is right?
Advertiser A may very well have found value and utilized Avg. Pos. well for their bidding, and Advertiser B may very well have ignored it for Search Impression Share and the like.
They may have both done very successfully and made their accounts money based off of these conflicting views of “necessary data.”
I ask again, who is right?
Well according to Google, whatever Google determines is important is the necessary data that all advertisers get in their accounts.
Do you see my concern here?
In not discussing this further, we are handing the platforms the ability to not simply automate our campaigns, but to determine what data is actually “necessary” for us to make “informed decisions” on.
“Just take your label-less medicine, and trust us… it will help you. We’re pretty sure. Until it doesn’t.”
Opinion B: The Algorithm Works Best When It’s Given Proper Guidelines
Okay, well that got complicated. What about the next set of contradictory but factual opinions on automation?
Let’s start with the opinion that resonates with us advertisers. That is, machine learning still needs humans for ongoing feedback, even after it’s created.
Now admittedly, I’ve heard this concept spoken of positively by platform reps as well. AFAIK, nearly everyone agrees that some sort of human guideline is necessary for automation.
Machine learning isn’t artificial intelligence (no matter how many people put AI on their websites), it relies on connected paths from past data points to make the best decisions. This also means it needs guidelines to *keep* it pointing in the right direction.
Free rein: “Make us money by spending money” told to a machine will release it on endless audiences looking for the chance to do just that.
It might work, but it could burn through a LOT of money and time while doing so.
Guideline: “Make us a 400% ROAS, while spending $100/day” suddenly sets essential guidelines around the machine’s intended path.
There are definitions for what success looks like, and by measuring past success from certain audiences, the machine can more easily identify potential wins based on that history + guidelines.
The Problem With Opinion B: The Algorithm Works Best When It’s Not Being Changed Unnecessarily
What could the problem with the above statement possibly be, especially since everyone agrees that some sort of guidelines is essential for automation?
The problem is back to the definition of what is actually necessary.
The worst thing for an algorithm is to get bad data.
The second worst thing is to change it when it doesn’t need to be changed. Manual tweaks have killed many an automated process.
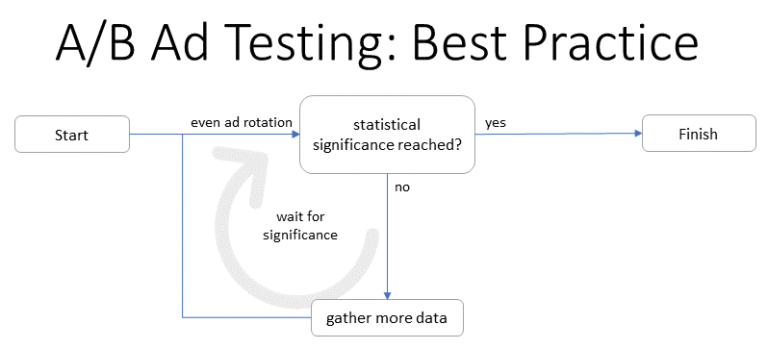
A great presentation on this concept was given by Martin Roettgerding at HeroConf London a few years back around ad testing in paid search.


In it, he demonstrated how many human ad testers often make decisions too quickly with too small an amount of data, whereas an automated process is more likely to see results average (and rise) over a longer period of time.
In other words, we humans can make changes unnecessarily, or without enough data, and mess up the algorithm.
Platform reps are rightfully concerned about giving an element of control over to humans who don’t fully understand the process.
It’s a difficult friction in which we can both agree that humans are necessary, and yet also agree that humans can mess it all up. Even intelligent, professional, well-intentioned PPCer humans.
Now What?
Here is where I would like to again make my request to the advertiser community.
We need to see the danger with platforms (such as Google and Facebook) in defining the “terms” of what data is necessary and beneficial, as well as obfuscating the process of the algorithms.
Going back to Smart Shopping (since it is often where my head is at these days), I have heard this excuse used by Google in order to prevent exceptionally helpful data like:
- Audience reporting (Who your ads are showing to).
- Placement reporting (Where your ads are showing… brand concerns anyone?).
- Search term reporting (What searches your audience made in order to show your ads).
- And even channel reporting (Are your ads showing on YouTube or Search?).
If we allow this by going quietly into the night, the platforms will define “necessary information” and “essential guidelines to the automation system” to be defined solely on how they want to define them.
They are in the business of making money, so certainly that will impact how those definitions are ultimately established.
When they’re the ones standing to benefit from any party in the auction and they’re the only ones who have any idea what’s happening in the auction, we shouldn’t be naive enough to expect them to do what is best for everyone else.
If anything, perhaps it would be better for automation if data remained available and advertiser control (the ones who own the data and accounts) maintain an element of control… even if it slows down the machine learning growth curve and introduces the potential for disaster at the hands of the wrong human guides.
Why is that… for the sake of avoiding the inevitability of our machine-overlord futures?
No, I think open data within the algorithm process and more control over of that process will:
- Allow for different strategies and tactics by different advertisers for the data, rather than forcing everyone into the same box (remember the Avg. Pos.example shared earlier)
- Avoid the inevitable unethical behavior that will result from entirely closed systems where, literally, billions of dollars are at stake. When that much money is at stake, and in an entirely closed system with only insight into it from internal teams (consider how easy it would be for Google to game a system with a data-driven attribution model applied to Smart Shopping campaigns), it’s impossible to imagine a future where someone at some point doesn’t use it for evil. It’s just too big a temptation.
Transparency and process can slow progress and efficiency down at times, but it can protect that progress and efficiency at the same time.
So, by all means, find problems with this article, discuss it and point out its logical holes, but for goodness’ sake, let’s shine increased light on the decreasing lack of data being handed to those paying for it in paid search at this time.
More Resources:
Image Credits
In-Post Image: Martin Roettgerding