
Live streaming is no stranger to fiasco and debacle. The world
over, there exists no fan of football, wrestling, or Game of
Thrones who hasn’t encountered the exasperating wheel-of-doom: the
video is buffering, and the action—maddeningly—grinds
unceremoniously to a halt. Indeed, as an audience, we’ve resigned
ourselves to the inexorability of service interruption, and on
occasion, to transmission failure outright.
Streaming doesn’t have to be this way.


In this first installment of a two-part blog series, we explore
some of the unique, oft-unappreciated challenges of transmitting
live, premium video over the open internet. While digital media
companies grapple with challenges both endogenous and exogenous,
internal and external, our focus will revolve around the
endogenous obstacles that are fully within the ability of
media firms to control, address, and ultimately surmount
Understanding the video distribution chain
Video feeds don’t simply materialize in a broadcaster or
operator’s headend. After the cameras capture the action, and
during the contribution stage—when video must travel
from the venue to a media company’s video-processing
facility—live transmissions are subjected to networks,
equipment, bandwidth, and codecs that vary venue to venue, and
event to event. Before a video feed has been ingested—to say
nothing of the feed’s being offloaded to a content distribution
network, or CDN – contribution serves as a major source of
latency.
The real fun begins post-ingest. Distribution regroups
two phases, each of which presents markedly different
bottlenecks.
The workflow portion of the distribution chain
comprises encoding, stream personalization, and ad insertion.
Workflow difficulties are intrinsically endogenous: the servers,
processing power, and architecture that define the workflow phase
fall directly under a media firm’s purview. Budget and economic
constraints aside, there is no excuse for mismanaging the content
workflow.
The delivery portion of the chain comprises delivery
to a CDN, and transmission across one or more
CDNs and ISP-owned access networks. Delivery, by contrast, is
largely exogenous: unforeseen congestion, peering issues,
CDN-to-CDN hand-off, and faulty network hops can introduce service
degradation that broadcasters and operators are near-powerless to
mitigate.
For their part, viewers tend to equate—however unfairly or
implicitly—any service interruption with delivery failure. This
apportioning of blame isn’t necessarily erroneous, but as an
industry, our concomitant tendency to focus on delivery masks a
multitude of workflow problems that can and demonstrably
do rear their ugly heads.
The discussion below examines why encoding is so difficult, and
how media companies should best address encoding’s unique
difficulties. It is difficult to overstate just how essential
encoding is to the live-streaming experience. The internet backbone
and ISP-owned networks aren’t made up of infinitely thick pipes.
Spectrum and bandwidth are limited resources, and encoding—the
act of compressing video into a smaller, digital footprint—is
the process that makes streaming video a non-rival good.
That’s because one’s consumption and viewership in live streaming
doesn’t preclude the ability of others to do the same.
The nature of the problem
The impediment to successfully encoding and delivering a live
stream hides in plain sight: live streaming isn’t remotely
fault-tolerant. In a video-on-demand (VoD) context, service
interruptions are an invitation to raid the fridge and procure a
tasty morsel. In a live context, such as sport, service
interruptions are an invitation to cancel one’s subscription and
find a new provider.
In turn, the complexity of encoding a live stream on the fly has
three principal determinants: resolution, frame rate, and bitrate.
For any given codec, complexity and processing requirements are an
increasing function of all three. An encoding system that cannot
handle a desired resolution, frame rate, and bitrate will introduce
buffering, producing pixelated, mottled video. Not nice.
At first blush, it may seem that purchasing heaps of encoders is
the panacea to untangle complexity and simplify processing. The
problem is that over-procuring compression resources is neither
efficient nor economically justifiable.
First, live audiences ebb and flow. Encoding resources that
cannot track demand and then scale to match both viewership spikes
and viewership valleys are inherently cost-inefficient.
Second, for any given audience size and for any given real-time
set of compression resources, the encoding process itself will
break down unless encoding needs—or the number of video bytes
that need to be compressed—can be matched against encoder
availability.
Third and finally, encoding resources and processing power are
rarely uniform. Unless intelligently managed, the process of
spreading encoding loads across encoding machines of disparate
capability can introduce additional and potentially severe
latency.
First principles and best practices
Real-time spikes in audience size are arguably the
defining characteristic of live events and live consumption. This
is why we we believe that cloud encoding—especially the ability
to spin up and spin down compression resources in
real-time—is an essential feature of any modern, live-streaming
video technology platform. For all but the rarest of corner cases,
inelastic, fixed-quantity, on-premise encoding builds are at odds
with today’s streaming-heavy, live-heavy market.
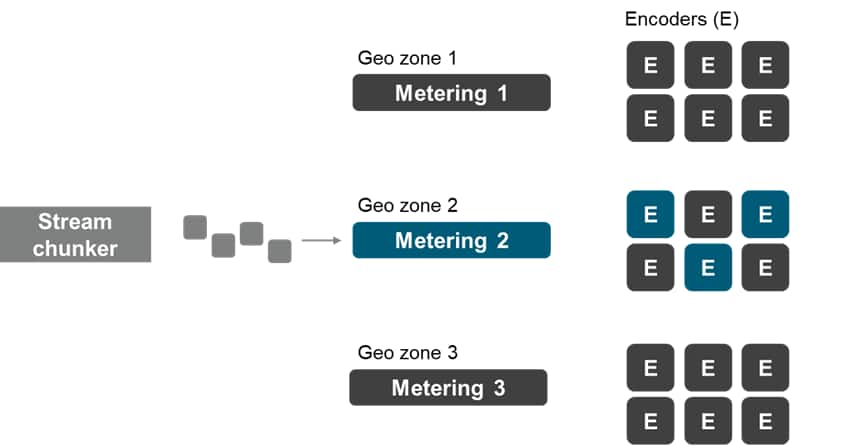

What of balancing encoding needs, and encoding demand, against
encoding and machine availability? Assuming—for the sake of
argument—that encoder-to-encoder capabilities are uniform,
live-streaming platforms still require a mechanism for distributing
encoding loads. Encoders can be, and do become, overburdened. Any
system that naively moves video to the same encoder, time and
again, will inevitably generate bottlenecks. We believe that
cloud-based compression workflows require a metering, brokering, or
trafficking system that dynamically allocates video to a multitude
of different encoders, based upon real-time encoder
availability.
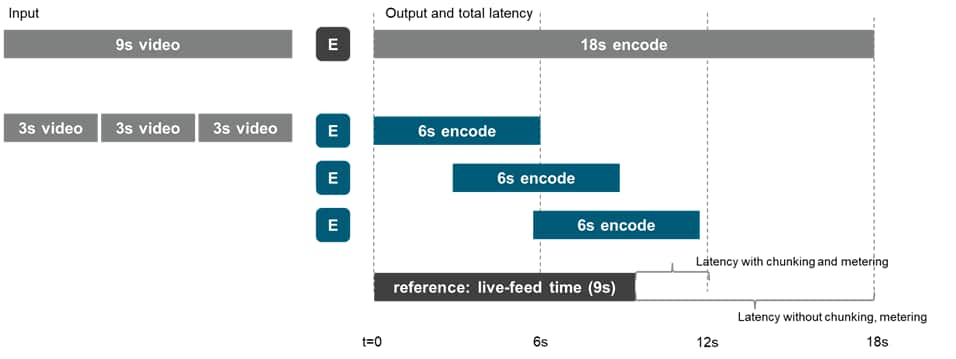
In the real world, of course, encoding capabilities are
manifestly not uniform. Suppose that a group of
encoders—for any given file length, measured in
seconds—takes twice as many seconds as the input file length to
perform and complete the encode. Why is metering so essential?
In the figure below, a single encoder—if dumped with a
9-second file—will take a minimum of 18 seconds to complete.
That is, relative to the live stream, the system generates 9
additional seconds of latency. By contrast, a system that chunks
video into small segments, and allocates these chunks
dynamically—even where chunks don’t begin the encode
process simultaneously, at time 0—will perform more
quickly, more predictably, and with less latency. In the same
figure, the chunk-and-allocate system takes roughly 12 seconds to
complete and generates a mere 3 seconds of latency.

We believe that metering, then, is essential in two respects.
First, regardless of variance in compression capabilities and
computational resources, metering systems refrain from
overburdening any single machine and ensure that the encoding
process overall doesn’t grind to a halt. Second, given that
capabilities do vary from machine to machine, metering
systems—in conjunction with a mechanism for slicing video files
into chunks—minimize latency.
In Part two of this series, we discuss how the remainder of the
content workflow, such as stream personalization and ad insertion,
can go wrong, and what to do about it.
Merrick Kingston is associate director for digital media
and video technology at IHS Markit | Technology, now a part of
Informa Tech
Posted 6 September 2019