![]()
Let’s face it – spiders are intimidating. Yet, when you’re in SEO, understanding how spiders crawl, index and render pages is vital to ensuring a site’s ability to flourish. Last week, Frédéric Dubut, senior program manager at Microsoft, broke down each concept for us at SMX East and explained how to optimize a site for crawl efficiency.
What is a crawler?
A crawler (also called a spider or bot) fetches HTML on the Internet for indexing. To better visualize, think large stores of computers sending a program to download content.
Okay, so what?
Well, here’s the thing. Dubut stressed that building a program to visit sites and fetch information is simple, building them to be polite – not so much. A crawler can (if they visit a server too often) degrade the performance of a website (i.e., slow down).
At the end of the day, search engines want crawlers to be “good citizen of the Internet.”
Crawl manager to the rescue!
What is a crawl manager?
Like most good supervisors, the crawl manager’s job is to listen to signals and set a budget. Its job is to estimate and determine “how much it can crawl a site without hurting the site’s performance?” (also called informally, “crawl budget”). When the crawl manager senses that it’s crawling too much, it will back off crawling. And when it still hasn’t identified a point of diminishing return, it will continue to increase the crawling.
What ‘signals’ does the crawl manager use?
The crawl manager reviews multiple levels. It uses signals (e.g., connection errors, download time, content size, status, etc.) to test the water and ensure that there are no anomalies. Each bottleneck layer has its own, independent crawl budget. To be crawled, all of these levels must have room within their crawl budget.
Levels include:
- Subdomain
- Domain
- Server
- IP Address
What is crawl budget?
Crawl budget is how much the crawler thinks it can crawl without hurting your site performance. It is determined through the iterative process of evaluating the metrics listed.
When should you be worried about the budget?
Dubut mentioned that there are two elements that make websites more challenging to crawl: size and optimization level (think: internal linking infrastructure, low duplicate content, strong signaling, etc.). The hardest websites to crawl are those that are large and have poor SEO, meaning that the budget is less than the demand (need to be crawled).
What can SEOs do to support the crawler?
- If you want to modify the time and rate of Bing’s crawler, use the Bing Webmaster Tools Crawl Control report (refer to the Configure My Site section). Author side note: Google’s documentation on changing Googlebot’s crawl rates.
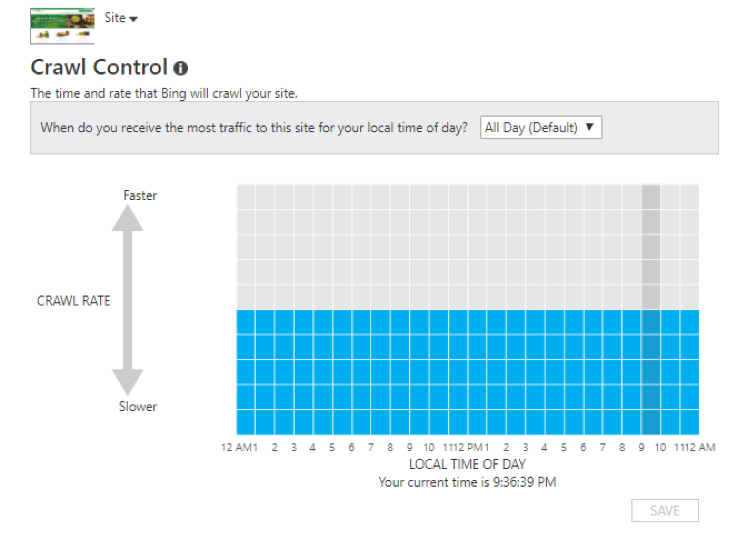
- Free up server resources by:
- Rejecting malicious actors through server-side security work.
- Finding ways to reduce crawl demand:
- Remove duplicate content or leverage canonical tags
- Consolidate redirect
- Use an XML sitemap (include “lastmod”)
- Remove unnecessary URL parameters
- Remove any junk URLs or unused resources
- Consider performance optimization for heavy, slow pages
- If leveraging a separate mobile configuration, consider responsive web design
- Since each bottleneck has its own crawl budget – monitor budget for each property, domain and IP (or IP range).
- During major URLs shifts, allow roughly two weeks to recrawl everything (as URL shifts are going to temporarily double crawl demand).
How does Bing’s crawler function (at a very abstract level)?
In the second portion of Dubut’s talk, he reiterated the importance of:
- Leveraging 301 redirects for permanent moves (302 redirects are only for temporary redirects).
- When a site uses a 301 redirect, the system treats it as permanent and shifts the scoring signal to the updated URL.

- A follow-up tweet from Dubut represents Bing’s 302 process best, “We interpret 301 vs. 302 quite literally to the standard. 302 targets don’t receive signals from the source, since they are supposed to be temporary and we don’t want to dilute signal. If the crawler sees it’s the same target again and again, then it may treat it as 301 anyway.”

- Resolving duplicate content.
- If both pages are the same, both will be crawled and indexed. One will be chosen.

- Not blocking search engines from resources needed to understand a webpage.
- If old pages are blocked within the robots.txt, the blocked URL will remain within the index. This will dilute signaling and potential impact of the URL.

Bing and JavaScript
The Bing team started working on JavaScript in 2011 with the idea that a limited portion (~5%) of the web would need to be rendered. As the web shifted towards being more JavaScript-heavy, the need to render a higher percentage of pages increased.
How does Bing handle JavaScript? What’s the rendering process?
Bing uses a headless browser and a crawl queue, which later renders content. The crawl queue is prioritized the same as anything else.
What should you do about JavaScript rendering issues?
- Don’t block resources necessary to understand the user experience in robots.txt.
- Make sure Bingbot is receiving content and allowed to access.
- If concerned about Bing’s ability to render content, use dynamic rendering to make JavaScript rendering more predictable. Side note: Confirm that a good faith effort is made to ensure the content is the same content served for users and bots.
What is currently in Bing’s queue?
Dubut also covered a few of Bing’s top initiatives for the next 12 months:
- Improving crawl efficiency.
- Crawl efficiency is the number of useful crawls (including: new pages, updated content, updated links, etc.) divided by the total number of crawls. Bing engineers’ bonuses will be tied to these numbers.
- Bing’s new blog series on maximizing crawl efficiency.
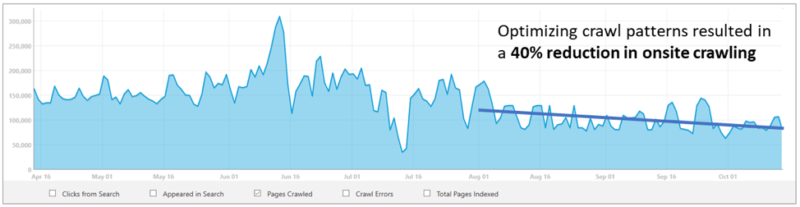
- Bing will be diving into how its team is improving its crawler. The blog covers how Bing was able to improve crawl efficiency by +40% on Cornell University Library, by saving resources on static, historical pages.

Walk through the slideshow presentation from SMX
Resources
Opinions expressed in this article are those of the guest author and not necessarily Search Engine Land. Staff authors are listed here.
About The Author

Alexis Sanders works as a Technical SEO Account Manager at Merkle. The technical SEO team ensures the accuracy, feasibility and scalability of the agency’s technical recommendations across all verticals. She is a contributor to the Moz blog, Search Engine Land, OnCrawl, and TechnicalSEO.com, creator of the TechnicalSEO.expert challenge, and during the day lives a normal life as an SEO account manager. Currently she’s been really passionate about developing knowledge of machine learning and data science.