

A smooth Black Friday is all we ask for
By the time I had my breakfast at about 8am Pacific Standard Time (PST) each day during the Black Friday weekend, Twilio SendGrid had already processed more than 1B emails as calculated in US Eastern Standard Time (EST).
Looking at the stats, we processed upwards of 16.5B emails from Thanksgiving to Cyber Monday, and upwards of 22.3B for the week starting on Tuesday before Thanksgiving. These are really good numbers for the business. From the perspective of an engineering organization, doing so without any alerts firing or any degraded customer experience was incredibly satisfying.
I recommend reading this blog article, Scaling Our Infrastructure for 4+ Billion Emails in a Single Day, written by my colleague Sara Saedinia, which talks about the importance of smoothly operating at this scale for our business and for the businesses that rely on us. Here, I am going to focus on our preparations that made the most critical weekend of the year for our email customers the smoothest one so far.
How did we make this a seamless Black Friday weekend? Handling our largest sending days requires diligent planning, numerous region swing tests, scores of people analyzing data, and tightening feedback loops as we validate improvements to our systems based on telemetry observations. We still have more automation and improvements that we will be making to ensure we continue to delight our customers and ensure we send the right communications to the right recipients expeditiously.
Understanding our business
SendGrid’s business model requires that we are always up—we don’t have maintenance windows for accepting and delivering mail. Our customers require a reliable service that accepts and delivers mail without interruption. This means that all our infrastructure changes, hardware as well as software, need to be done while we continue processing and delivering emails without any noticeable delay.
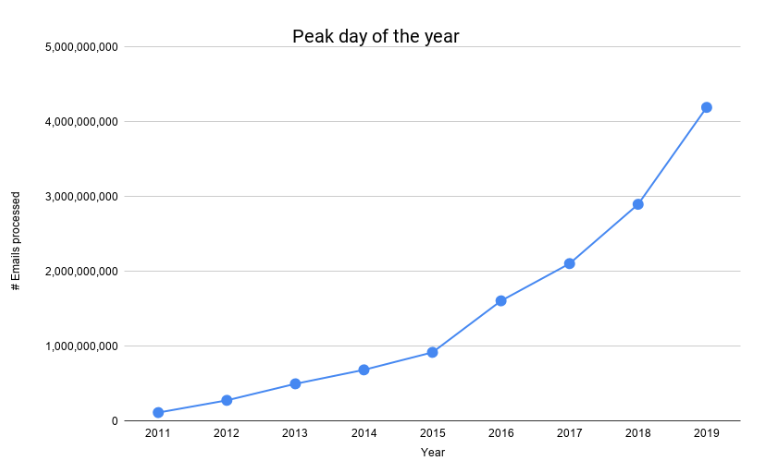
The number of emails we process has grown tremendously over the past few years as the following graph depicts.

We had our first 1B day in mid-2016, and we had our first 4B day this Black Friday. That is 400% growth in less than 4 years. To account for our ever-increasing scale, to keep our costs manageable, and to provide greater reliability for our customers, we have had to redesign and evolve our mail processing pipeline.
Black Friday is coming
People ask me, “Why are Black Friday and Cyber Monday so important to you?” This Cyber Monday, we processed 45% more emails than the previous year’s peak. Black Friday is one of the most important retail and spending events in the United States. Traditionally, it is the day when the retailers will be in the black (net positive) for the year. Email marketing and the use of transactional emails have become critical for all businesses.
From retailers to the businesses that provide marketing automation, having problems reliably delivering emails on Black Friday weekend can result in significant revenue loss. As a result, this weekend is often a business defining weekend for us. We do our best to make it as easy as we can for our engineers, support agents, customer success managers, executives, and most importantly, for our customers.
Preparing for Black Friday
So how do we prepare for Black Friday? We buy t-shirts! (And do a ton of work.) Read on for how we prepare.
Members of the Twilio SendGrid Irvine Office
![]()



Some of the members of Twilio SendGrid Denver office.
![]()


Stats
Let’s start with some stats:
- Processed 4.1B+ emails on Black Friday and 4.2B+ emails on Cyber Monday
- Processed 16.5B+ emails from Thanksgiving to Cyber Monday
- Processed 315M+ emails during the peak hour
- Black Friday and Cyber Monday, each had 8 successive hours processing 220M emails or more
- All this with a median end to end time of deliverable emails at 1.9 seconds
- On average, we roughly emit 5.5 events per message. Based on that, our systems emitted and processed 91B+ events from Thanksgiving to Cyber Monday, 23B+ on Cyber Monday alone
The Challenges
Never before seen scale: The scale that we target to test must match our predicted peak load. When we did our first test for this past year’s preparation in early April, our average weekday volume was less than half of our peak prediction. Our hourly peaks were not even half of what we would be testing for.
Managing our environments: Email is a stateful workflow: it is necessary to keep track of the state of a message. So as the message moves through the pipeline, we track if it bounces or gets deferred, and prevent duplication. As such, our mail pipeline is a hybrid cloud and on-premise architecture, and autoscaling is not a magic fix. Our challenge is to maximize efficiencies of our data-center services while preparing capacity to handle massive volume spikes without impacting the cost to customers.
Scaling is not linear: Not all systems scale linearly. Since our predicted scale is so much higher than when we first start testing, we can’t just calculate our hardware needs by a simple mathematical model. It is also important to remember that blindly scaling services would overload dependencies, and dependencies like the database don’t scale the same way as our mail transfer agent (MTA).
Balancing our investments: As we continue to innovate, ensuring that we support customer needs related to their email delivery, we understand that our features don’t provide our customers any value if they aren’t accessible and performing as needed. We have to find a balance and invest appropriately in testing, learning, upgrading, and improving our systems to be reliable and resilient at our scale. Doing so efficiently allows us to continue investing in innovation.
How did we do it?
We did it together, as one team. Arm-in-arm, as we say. Our preparations this year, from April through November, involved participation of more than 100 members across many teams. Modeling peak predictions, defining observability criteria, learning from our observations, engineering the necessary changes, planning, and managing requires various skills from multiple people.
We trusted each other while keeping each other honest, staying focused, and delivering our goals.
An effective and constantly improving process was our friend.
Planning
We have three data centers to process customer’s emails. In order to plan for an unreached scale, we validate that we can handle our peak projected traffic with only two data centers available. In order to meet our high availability SLA, our infrastructure has built-in region failover. This means that we have the ability to failover traffic between regions.
We leverage this capability with a frequent cadence throughout the year as a standard operating procedure and accelerate it as part of our efforts to demonstrate we are able to serve Black Friday/Cyber Monday peak volumes while maintaining quality of service. If system telemetry approaches the threshold of our service-level objective (SLO), we are able to quickly leverage multiple regions to resume nominal state. We then leverage the collected telemetry to determine where we need to make changes.
In a parallel effort, we had started reviewing and solidifying our Service Level Objectives (SLOs) that provide us with a precise numerical target for system availability and our Service Level Indicators (SLIs), which provide us the frequency of successful probes to our systems.
Observations, learnings, and communication
Each test provided a large amount of information. One of the challenges that we faced was effectively documenting and communicating the observations across the rotating test teams, and then analyzing the data across multiple systems. Although we have standard team dashboards, each member could have something specific they observe.
We started doing a retro with the test teams to analyze all the technical information dumped for multiple services managed by multiple teams. These retros were long, and for most of the duration, were only useful to one or two teams per test. We eventually moved to using a Slack Thread for retro notes saving 10s of human hours of meeting time per test.
Our test management team involved two engineering managers, one architect and one senior engineer. The managers were pivotal in planning and dependency management, while the more technical folks helped process and analyze the information at end to end system level.
Based on the analysis of the available information, we iteratively validated that our SLIs were strictly conforming to our SLOs. We fine tuned our alerts and made certain critical alerts more sensitive in order to identify any potential system degradation well in advance.
Prioritization and implementation
We ticketed proposed changes and the teams prioritized these tickets. The first challenge here was to manage these tickets across multiple team boards. Another challenge was to ruthlessly prioritize the Black Friday work against other priorities.
We needed to provide our engineers the creative freedom to come up with solutions to difficult problems. At the same time, we had to make sure that these solutions aligned with our long term plans. It was also very critical that we were always conscious of any conflict of interest, which meant avoiding any short term solutions that could come back to bite us.
Validating the changes that were implemented would become our objective for upcoming tests.
Maintaining and upping the tempo as we came closer to Black Friday was a major challenge in planning and execution.
The acceleration
As we entered September, we started executing multiple stress tests each week. This required us to identify, fix, and validate issues faster. It also provided us with a much faster learning and adapting cycle.
In addition to the full swing test of the mail pipeline as described earlier, we also started stress testing our supporting services during the same time. During the same period we started conducting load tests with one of our largest customers to ensure that our incoming geopods would handle their anticipated burst sends during the holiday season without any concerns.
Due to the long hours and the challenge of managing the work, our teams were getting burnt out. We listed out the most critical alerts required to stop our test if necessary, and made them more sensitive. This allowed us to start doing our tests without requiring us to be present to monitor our systems early in the morning.
Speed with caution
As we approached the end of September, there was a concern that we may not be moving fast enough in the right direction. We created a tiger team, a team of specialists that could work on any of the tickets across multiple teams, and one that worked with much leaner process at a daily level.
We made significant improvements in our operational infrastructure as well as our mail processing software in preparation of Black Friday. These changes were being expressly prioritized, and the teams had to work in a great coordination with each other. It was a great experience for folks putting SendGrid first. We were making changes to the applications, infrastructure, and increasing our hardware capacity while running the core engine of a business unit of a public company all at a startup pace. Best of all, we did it all without any degraded service experience for our customers.
Future Plans
We spent a lot of human hours preparing for the Black Friday 2019. Our learnings from this year will help us to automate much of our preparation for Black Friday and Cyber Monday in 2020. We look forward to another successful year topped with stress free, record-breaking volumes of holiday sending for our customers and our employees.