
Curious AI: algorithms powered with intrinsic motivation.
What does Curiosity-driven AI mean? Research and innovation in AI made us accustomed with novelty and breakthroughs practically coming out on a daily basis. Now we are almost used to algorithms that can recognize scenes and environments in real-time and move accordingly, who can understand natural language (NLP), learn manual work directly from the observation, “invent” video with well-known characters reconstructing synchronized mimics to audio, to imitate the human voice in even non-trivial dialogues, and even to develop new AI algorithms by themselves(!).
People talk too much. Humans aren’t descended from monkeys. They come from parrots. (The shadow of the wind – Carlos Ruiz Zafón)
All very beautiful and impressive (or disturbing, depending on the point of view). However, there was something that was still missing: after all, even with the ability to self-improve up to achieve comparable or even superior results to those of human beings, all these performances always started from human input. That is, it is always the humans who decide to try their hand at a given task, to prepare the algorithms, and to “push” the AI towards a given direction. After all, even totally autonomous cars always need to receive a destination to reach. In other words, no matter how perfect or autonomous the execution is: motivation is still substantially human.
no matter how perfect or autonomous the execution is: motivation is still substantially human.
What is “motivation”? From a psychological point of view, it is the “spring” that pushes us towards a certain behavior. Without going into the myriad of psychological theories in this regard (the article by Ryan and Deci can be a good starting point for those interested in looking into it, other than the Wikipedia entry), we can generically distinguish between extrinsic motivation, where the individual is motivated by external rewards, and intrinsic motivation, where the drive to act derives from forms of inner gratification.
:max_bytes(150000):strip_icc()/2795384-differences-between-extrinsic-and-intrinsic-motivation-5ae76997c5542e0039088559.png)
These “rewards” or gratifications are conventionally called ” reinforcements “, which can be positive (rewards), or negative (punishments), and are a powerful mechanism of learning, so it is not surprising that it has also been exploited in Machine Learning,
Reinforcement Learning
DeepMind’s AlphaGo was the most amazing example of the results that can be achieved with reinforcement learning, and even before that DeepMind itself had presented surprising results with an algorithm that learned to play video games alone (the algorithm knew almost nothing of the rules and the environment of the game).
However, this kind of algorithm required an immediate form of reinforcement for learning: [right attempt] – [reward] – [more likely to repeat it] – – [punishment] – [less chance of falling back]. The machine receives feedback on the outcome (e.g. the score) instantly, so it is able to elaborate strategies that lead to optimization towards the greatest amount of “rewards” possible. This situation in a sense resembles the problem with corporate incentives: they are very effective, but not always in the direction that would have been expected (e.g. the attempt to provide the programmers with incentives by lines of code, which proved very effective in encouraging the length of the code, instead of the quality, which was the intention).

However, in the real world external reinforcements are often rare, or even absent, and in these cases, curiosity can work as an intrinsic reinforcement (internal motivation) to trigger an exploration of the environment and learn skills that can come in handy later.
Last year a group of researchers from the University of Berkeley published a remarkable paper, probably destined to push forward the limits of machine learning, whose title was Curiosity Driven Exploration by Self-supervised Prediction. Curiosity in this context was defined as “the error in an agent’s ability to predict the consequence of its own actions in a visual feature space learned by a self-supervised inverse dynamics model”. In other words, the agent creates a model of the environment he is exploring, and the error in the predictions (the difference between model and reality) would consist in the intrinsic reinforcement encouraging the curiosity of exploration.
The research involved three different settings:
- “Sparse extrinsic reward”, or extrinsic reinforcements supplied with low frequency.
- Exploration without extrinsic reinforcements.
- Generalization of unexplored scenarios (e.g. new levels of the game), where the knowledge gained from the previous experience facilitates a faster exploration that does not start from scratch.
As you can see from the video above, the agent with intrinsic curiosity is able to complete Level 1 of SuperMario Bros and VizDoom with no problems whatsoever, while the one without it often tends to clash with the walls, or get stuck in some corner.
Intrinsic Curiosity Module (ICM)
What the authors propose is the Intrinsic Curiosity Module (ICM), which uses the methodology of asynchronous gradients A3C proposed by Minh et al. for determining the policies to be pursued.
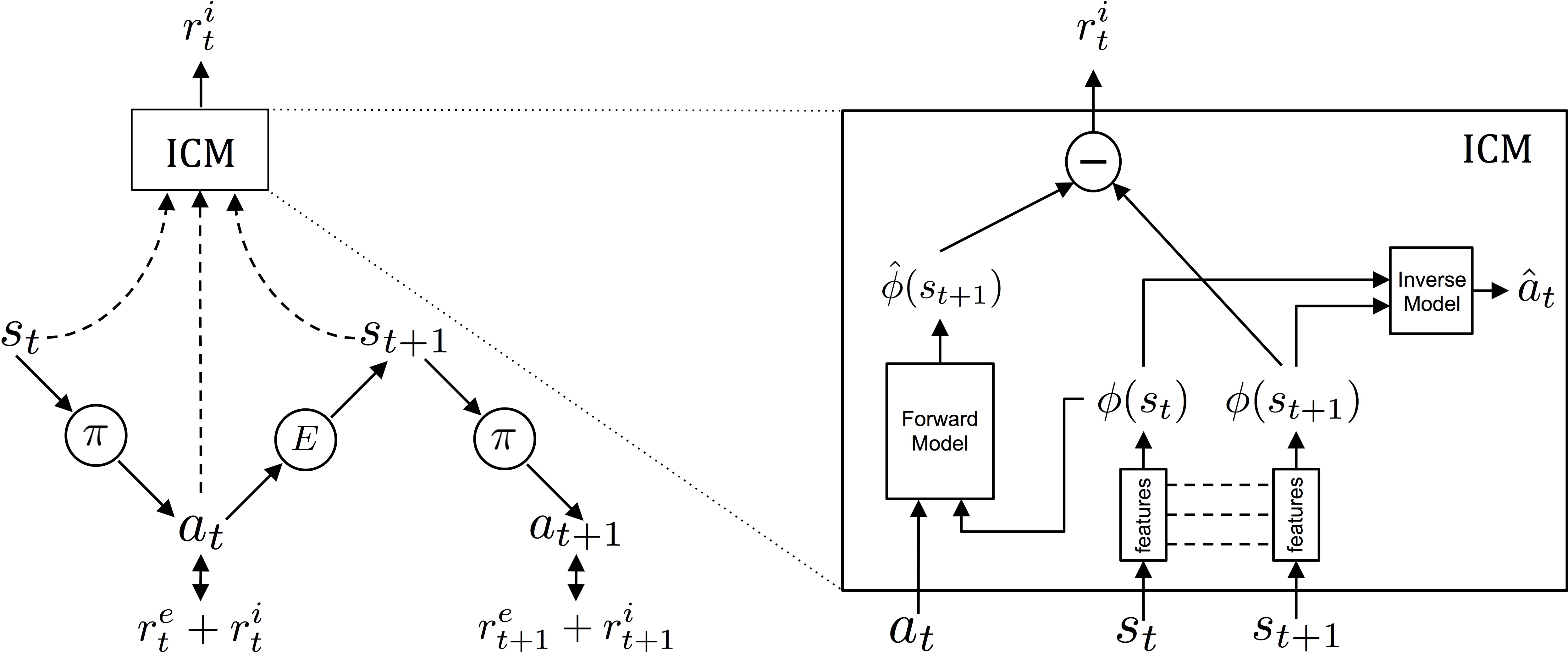
Here Above, I presented the conceptual diagram of the module: on the left it shows how the agent interacts with the environment in relation to the policy and the reinforcements it receives. The agent is in a certain state st, and executes the action αt according to with plan π. The action αt will eventually receive intrinsic and extrinsic reinforcements (ret+rit) and will modify the environment E leading to a new state st+1… and so on.
On the right there is a cross-section of ICM: a first module converts the raw states st of the agent into features φ(st) that can be used in the processing. Subsequently, the inverse dynamics module (inverse model) uses the features of two adjacent states φ(st) and φ (st+1) to predict the action that the agent has performed to switch from one state to another.
At the same time, another sub-system (forward model) is also trained, which predicts the next feature starting from the last action of the agent. The two systems are optimized together, meaning that Inverse Model learns features that are relevant only to the agent’s forecasts, and the Forward Model learns to make predictions about these features.
So what?
The main point is that since there are no reinforcements for environmental features that are inconsequential to the actions of the agent, the learned strategy is robust to uncontrollable environmental aspects (see the example with white noise in the video).
In order to understand each other better, the real reinforcement of the agent here is curiosity, that is, the error in the prediction of environmental stimuli: the greater the variability, the more errors the agent will make in predicting the environment, the greater the intrinsic reinforcement, keeping the “curious” agent.

The reason for the extraction of the features mentioned above is that making pixel-based predictions is not only very difficult, but it makes the agent too fragile to noise or elements that are not very relevant. Just to give an example, if, during an exploration the agent would get in front of trees with leaves blowing in the wind, the agent would risk fixating on the leaves for the sole reason that they are difficult to predict, neglecting everything else. ICM instead provides us with features extracted autonomously from the system (basically in a self-supervised way), resulting in the robustness we were mentioning.
Generalization
The model proposed by the authors makes a significant contribution to research on curiosity-driven exploration, as using self-extracted features instead of predicting pixels, make the system almost immune to noise and irrelevant elements, avoiding going into blind alleys.

However, that’s not all: this system, in fact, able to use the knowledge acquired during exploration to improve performance. In the figure above the agent manages to complete SuperMario Bros level 2 much faster thanks to the “curious” exploration carried out in level 1, while in VizDoom he was able to walk the maze very quickly without crashing into the walls.
In SuperMario the agent is able to complete 30% of the map without any kind of extrinsic reinforcement. The reason, however, is that at 38% there is a chasm that can only be overcome by a well-defined combination of 15-20 keys: the agent falls and dies without any kind of information on the existence of further portions of the explorable environment. The problem is not in itself connected to learning by curiosity, but it is certainly a stumbling block that needs to be solved.
Notes
The learning policy, which in this case is the Asynchronous Advantage Actor Critic (A3C) model of Minh et al. The policy subsystem is trained to maximize the reinforcements ret+rit (where ret is near to zero).
Links
Richard M. Ryan, Edward L. Deci: Intrinsic and Extrinsic Motivations: Classic Definitions and New Directions. Contemporary Educational Psychology 25, 54–67 (2000), doi:10.1006/ceps.1999.1020.
In search of the evolutionary foundations of human motivation
D. Pathak et al. Curiosity-driven Exploration by Self-supervised Prediction. arXiv 1705.05363
CLEVER MACHINES LEARN HOW TO BE CURIOUS (AND PLAY SUPER MARIO BROS.)
I. M. de Abril, R. Kanai: Curiosity-driven reinforcement learning with homeostatic regulation – arXiv 1801.07440
Researchers Have Created an AI That Is Naturally Curious
V. Mnih et al.: Asynchronous Methods for Deep Reinforcement Learning – arXiv:1602.01783
Asynchronous Advantage Actor Critic (A3C) – Github (source code)
Asynchronous methods for deep reinforcement learning – the morning paper
{kind=link}
The 3 tricks that made AlphaGo Zero work