In a paper published on the preprint server Arxiv.org, researchers at Facebook describe wav2vec 2.0, an improved framework for self-supervised speech recognition. They claim it demonstrates for the first time that learning representations from speech, followed by fine-tuning on transcribed speech, can outperform the best semi-supervised methods while being conceptually simpler, achieving state-of-the-art results using just 10 minutes of labeled data and pretraining on 53,000 hours of unlabeled data.
AI models benefit from large amounts of labeled data — it’s how they learn to infer patterns and make predictions. However, as the coauthors of the paper note, labeled data is generally harder to come by than unlabeled data. Current speech recognition systems require thousands of hours of transcribed speech to reach acceptable performance, which isn’t available for the majority of the nearly 7,000 languages spoken worldwide. Facebook’s original wav2vec and other systems attempt to sidestep this with self-supervision, which generates labels automatically from data. But they’ve fallen short in terms of performance compared with semi-supervised methods that combine a small amount of labeled data with a large amount of unlabeled data during training.
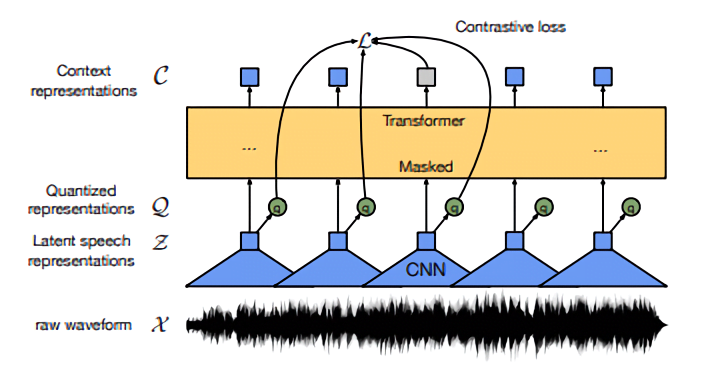
Wav2vec 2.0 ostensibly closes the gap with an encoder module that takes raw audio and outputs speech representations, which are fed to a Transformer that ensures the representations capture whole-audio-sequence information. Created by Google researchers in 2017, the Transformer network architecture was initially intended as a way to improve machine translation. To this end, it uses attention functions instead of a recurrent neural network to predict what comes next in a sequence. This characteristic enables wav2vec 2.0 to build context representations over continuous speech representations and record statistical dependencies over audio sequences end-to-end.

Above: A diagram illustrating wav2vec 2.0’s architecture.
To pretrain wav2vec 2.0, the researchers masked portions of the speech representations (approximately 49% of all time steps with a mean span length of 299 milliseconds) and tasked the system with predicting them correctly. Then, to fine-tune it for speech recognition, they added a projection on top of wav2vec 2.0 representing vocabulary in the form of tokens for characters and word boundaries (e.g., word spaces of written English) before performing additional masking during training.
The coauthors trained wav2vec 2.0 on several unlabeled and labeled data sources for up to 5.2 days at a time on 128 Nvidia V100 graphics cards to evaluate the system’s performance. Fine-tuning took place on between eight and 24 graphics cards.
According to the team, the largest trained wav2vec 2.0 model — which was fine-tuned on only 10 minutes of labeled data (48 recordings with an average length of 12.5 seconds) — achieved a word error rate of 5.7 on the open source Librispeech corpus. (Here, “word error rate” refers to the number of errors divided by total words.) On a 100-hour subset of Librispeech, the same model managed a word error rate of 2.3 — 45% lower than the previous state of the art trained with 100 times less labeled data — and 1.9 when fine-tuned on even more data, a result competitive with top semi-supervised methods that rely on more sophisticated architectures.
“[This] demonstrates that ultra-low resource speech recognition is possible with self-supervised learning on unlabeled data,” the researchers wrote. “We have shown that speech recognition models can be built with very small amounts of annotated data at very good accuracy. We hope our work will make speech recognition technology more broadly available to many more languages and dialects.”
Facebook used the original wav2vec to provide better audio data representations for keyword spotting and acoustic event detection and to improve its systems that proactively identify posts in violation of its community guidelines. It’s likely wav2vec 2.0 will be applied to the same tasks; beyond this, the company says it plans to make the models and code available as an extension to its fairseq modeling toolkit.