It has been a while since Google has had a major algorithm update.
They recently announced one which began on the 12th of March.
This week, we released a broad core algorithm update, as we do several times per year. Our guidance about such updates remains as we’ve covered before. Please see these tweets for more about that:https://t.co/uPlEdSLHoXhttps://t.co/tmfQkhdjPL— Google SearchLiaison (@searchliaison) March 13, 2019
What changed?
It appears multiple things did.
When Google rolled out the original version of Penguin on April 24, 2012 (primarily focused on link spam) they also rolled out an update to an on-page spam classifier for misdirection.

And, over time, it was quite common for Panda & Penguin updates to be sandwiched together.
If you were Google & had the ability to look under the hood to see why things changed, you would probably want to obfuscate any major update by changing multiple things at once to make reverse engineering the change much harder.
Anyone who operates a single website (& lacks the ability to look under the hood) will have almost no clue about what changed or how to adjust with the algorithms.
In the most recent algorithm update some sites which were penalized in prior “quality” updates have recovered.

Though many of those recoveries are only partial.
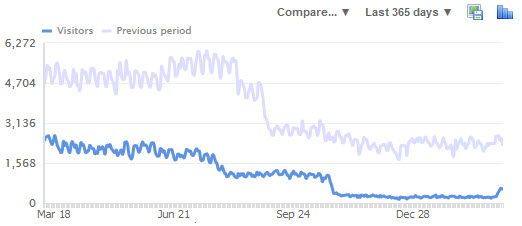
Many SEO blogs will publish articles about how they cracked the code on the latest update by publishing charts like the first one without publishing that second chart showing the broader context.
The first penalty any website receives might be the first of a series of penalties.
If Google smokes your site & it does not cause a PR incident & nobody really cares that you are gone, then there is a very good chance things will go from bad to worse to worser to worsterest, technically speaking.
“In this age, in this country, public sentiment is everything. With it, nothing can fail; against it, nothing can succeed. Whoever molds public sentiment goes deeper than he who enacts statutes, or pronounces judicial decisions.” – Abraham Lincoln
Absent effort & investment to evolve FASTER than the broader web, sites which are hit with one penalty will often further accumulate other penalties. It is like compound interest working in reverse – a pile of algorithmic debt which must be dug out of before the bleeding stops.
Further, many recoveries may be nothing more than a fleeting invitation to false hope. To pour more resources into a site that is struggling in an apparent death loop.
The above site which had its first positive algorithmic response in a couple years achieved that in part by heavily de-monetizing. After the algorithm updates already demonetized the website over 90%, what harm was there in removing 90% of what remained to see how it would react? So now it will get more traffic (at least for a while) but then what exactly is the traffic worth to a site that has no revenue engine tied to it?
That is ultimately the hard part. Obtaining a stable stream of traffic while monetizing at a decent yield, without the monetizing efforts leading to the traffic disappearing.
A buddy who owns the above site was working on link cleanup & content improvement on & off for about a half year with no results. Each month was a little worse than the prior month. It was only after I told him to remove the aggressive ads a few months back that he likely had any chance of seeing any sort of traffic recovery. Now he at least has a pulse of traffic & can look into lighter touch means of monetization.
If a site is consistently penalized then the problem might not be an algorithmic false positive, but rather the business model of the site.
The more something looks like eHow the more fickle Google’s algorithmic with receive it.
Google does not like websites that sit at the end of the value chain & extract profits without having to bear far greater risk & expense earlier into the cycle.
Thin rewrites, largely speaking, don’t add value to the ecosystem. Doorway pages don’t either. And something that was propped up by a bunch of keyword-rich low-quality links is (in most cases) probably genuinely lacking in some other aspect.
Generally speaking, Google would like themselves to be the entity at the end of the value chain extracting excess profits from markets.
This is the purpose of the knowledge graph & featured snippets. To allow the results to answer the most basic queries without third party publishers getting anything. The knowledge graph serve as a floating vertical that eat an increasing share of the value chain & force publishers to move higher up the funnel & publish more differentiated content.
As Google adds features to the search results (flight price trends, a hotel booking service on the day AirBNB announced they acquired HotelTonight, ecommerce product purchase on Google, shoppable image ads just ahead of the Pinterest IPO, etc.) it forces other players in the value chain to consolidate (Expedia owns Orbitz, Travelocity, Hotwire & a bunch of other sites) or add greater value to remain a differentiated & sought after destination (travel review site TripAdvisor was crushed by the shift to mobile & the inability to monetize mobile traffic, so they eventually had to shift away from being exclusively a reviews site to offer event & hotel booking features to remain relevant).
It is never easy changing a successful & profitable business model, but it is even harder to intentionally reduce revenues further or spend aggressively to improve quality AFTER income has fallen 50% or more.
Some people do the opposite & make up for a revenue shortfall by publishing more lower end content at an ever faster rate and/or increasing ad load. Either of which typically makes their user engagement metrics worse while making their site less differentiated & more likely to receive additional bonus penalties to drive traffic even lower.
In some ways I think the ability for a site to survive & remain though a penalty is itself a quality signal for Google.
Some sites which are overly reliant on search & have no external sources of traffic are ultimately sites which tried to behave too similarly to the monopoly that ultimately displaced them. And over time the tech monopolies are growing more powerful as the ecosystem around them burns down:
If you had to choose a date for when the internet died, it would be in the year 2014. Before then, traffic to websites came from many sources, and the web was a lively ecosystem. But beginning in 2014, more than half of all traffic began coming from just two sources: Facebook and Google. Today, over 70 percent of traffic is dominated by those two platforms.
Businesses which have sustainable profit margins & slack (in terms of management time & resources to deploy) can better cope with algorithmic changes & change with the market.
Over the past half decade or so there have been multiple changes that drastically shifted the online publishing landscape:
- the shift to mobile, which both offers publishers lower ad yields while making the central ad networks more ad heavy in a way that reduces traffic to third party sites
- the rise of the knowledge graph & featured snippets which often mean publishers remain uncompensated for their work
- higher ad loads which also lower organic reach (on both search & social channels)
- the rise of programmatic advertising, which further gutted display ad CPMs
- the rise of ad blockers
- increasing algorithmic uncertainty & a higher barrier to entry
Each one of the above could take a double digit percent out of a site’s revenues, particularly if a site was reliant on display ads. Add them together and a website which was not even algorithmically penalized could still see a 60%+ decline in revenues. Mix in a penalty and that decline can chop a zero or two off the total revenues.
Businesses with lower margins can try to offset declines with increased ad spending, but that only works if you are not in a market with 2 & 20 VC fueled competition:
Startups spend almost 40 cents of every VC dollar on Google, Facebook, and Amazon. We don’t necessarily know which channels they will choose or the particularities of how they will spend money on user acquisition, but we do know more or less what’s going to happen. Advertising spend in tech has become an arms race: fresh tactics go stale in months, and customer acquisition costs keep rising. In a world where only one company thinks this way, or where one business is executing at a level above everyone else – like Facebook in its time – this tactic is extremely effective. However, when everyone is acting this way, the industry collectively becomes an accelerating treadmill. Ad impressions and click-throughs get bid up to outrageous prices by startups flush with venture money, and prospective users demand more and more subsidized products to gain their initial attention. The dynamics we’ve entered is, in many ways, creating a dangerous, high stakes Ponzi scheme.
And sometimes the platform claws back a second or third bite of the apple. Amazon.com charges merchants for fulfillment, warehousing, transaction based fees, etc. And they’ve pushed hard into launching hundreds of private label brands which pollute the interface & force brands to buy ads even on their own branded keyword terms.
They’ve recently jumped the shark by adding a bonus feature where even when a brand paid Amazon to send traffic to their listing, Amazon would insert a spam popover offering a cheaper private label branded product:
Amazon.com tested a pop-up feature on its app that in some instances pitched its private-label goods on rivals’ product pages, an experiment that shows the e-commerce giant’s aggressiveness in hawking lower-priced products including its own house brands. The recent experiment, conducted in Amazon’s mobile app, went a step further than the display ads that commonly appear within search results and product pages. This test pushed pop-up windows that took over much of a product page, forcing customers to either click through to the lower-cost Amazon products or dismiss them before continuing to shop. … When a customer using Amazon’s mobile app searched for “AAA batteries,” for example, the first link was a sponsored listing from Energizer Holdings Inc. After clicking on the listing, a pop-up window appeared, offering less expensive AmazonBasics AAA batteries.”
Buying those Amazon ads was quite literally subsidizing a direct competitor pushing you into irrelevance.
As the market caps of big tech companies climb they need to be more predatious to grow into the valuations & retain employees with stock options at an ever-increasing price.
They’ve created bubbles in their own backyards where each raise requires another. Teachers either drive hours to work or live in houses subsidized by loans from the tech monopolies that get a piece of the upside (provided they can keep their own bubbles inflated).
“It is an uncommon arrangement — employer as landlord — that is starting to catch on elsewhere as school employees say they cannot afford to live comfortably in regions awash in tech dollars. … Holly Gonzalez, 34, a kindergarten teacher in East San Jose, and her husband, Daniel, a school district I.T. specialist, were able to buy a three-bedroom apartment for $610,000 this summer with help from their parents and from Landed. When they sell the home, they will owe Landed 25 percent of any gain in its value. The company is financed partly by the Chan Zuckerberg Initiative, Mark Zuckerberg’s charitable arm.”
The above sort of dynamics have some claiming peak California:
The cycle further benefits from the Alchian-Allen effect: agglomerating industries have higher productivity, which raises the cost of living and prices out other industries, raising concentration over time. … Since startups raise the variance within whatever industry they’re started in, the natural constituency for them is someone who doesn’t have capital deployed in the industry. If you’re an asset owner, you want low volatility. … Historically, startups have created a constant supply of volatility for tech companies; the next generation is always cannibalizing the previous one. So chip companies in the 1970s created the PC companies of the 80s, but PC companies sourced cheaper and cheaper chips, commoditizing the product until Intel managed to fight back. Meanwhile, the OS turned PCs into a commodity, then search engines and social media turned the OS into a commodity, and presumably this process will continue indefinitely. … As long as higher rents raise the cost of starting a pre-revenue company, fewer people will join them, so more people will join established companies, where they’ll earn market salaries and continue to push up rents. And one of the things they’ll do there is optimize ad loads, which places another tax on startups. More dangerously, this is an incremental tax on growth rather than a fixed tax on headcount, so it puts pressure on out-year valuations, not just upfront cash flow.
If you live hundreds of miles away the tech companies may have no impact on your rental or purchase price, but you can’t really control the algorithms or the ecosystem.
All you can really control is your mindset & ensuring you have optionality baked into your business model.
- If you are debt-levered you have little to no optionality. Savings give you optionality. Savings allow you to run at a loss for a period of time while also investing in improving your site and perhaps having a few other sites in other markets.
- If you operate a single website that is heavily reliant on a third party for distribution then you have little to no optionality. If you have multiple projects that enables you to shift your attention toward working on whatever is going up and to the right while letting anything that is failing pass time without becoming overly reliant on something you can’t change. This is why it often makes sense for a brand merchant to operate their own ecommerce website even if 90% of their sales come from Amazon. It gives you optionality should the tech monopoly become abusive or otherwise harm you (even if the intent was rather than outright misanthropic).
As the update ensues Google will collect more data with how users interact with the result set & determine how to weight different signals, along with re-scoring sites that recovered based on the new engagement data.
Recently a Bing engineer named Frédéric Dubut described how they score relevancy signals used in updates
As early as 2005, we used neural networks to power our search engine and you can still find rare pictures of Satya Nadella, VP of Search and Advertising at the time, showcasing our web ranking advances. … The “training” process of a machine learning model is generally iterative (and all automated). At each step, the model is tweaking the weight of each feature in the direction where it expects to decrease the error the most. After each step, the algorithm remeasures the rating of all the SERPs (based on the known URL/query pair ratings) to evaluate how it’s doing. Rinse and repeat.
That same process is ongoing with Google now & in the coming weeks there’ll be the next phase of the current update.
So far it looks like some quality-based re-scoring was done & some sites which were overly reliant on anchor text got clipped. On the back end of the update there’ll be another quality-based re-scoring, but the sites that were hit for excessive manipulation of anchor text via link building efforts will likely remain penalized for a good chunk of time.