

July 2, 2018
 |



NOTE: Please use these links to catch up on the previous posts in the series: Article 1 / Article 2 / Article 3 / Article 4 / Article 5
By: Denica Masby & Cindy Krum
At MobileMoxie, we believe that Mobile-First Indexing represents a fundamental shift in how Google organizes information and processes queries. Further, we speculate that the shift to Mobile-First Indexing took Google more time than they originally expected, partially because they did not anticipate the level of complexity that this shift would have, when different languages and locations were taken into account, to make the change viable world-wide.
This is the fourth article in a five-part series about the relationship between Entity Understanding and language in search. The first three articles in this series focused on what Entity-First Indexing is, how Google managed to re-index the content of the web this way, and how it makes things like language detection more important in search. This article continues the focuses on practical research that MobileMoxie completed, testing international searches for Entity Understanding to outline the impact of language and localization in the query results. It provides more deep insights about how linguistic factors impact Google’s algorithmic Query Understanding; Specifically, our research in this article focuses on how and when Google’s advanced Cloud Natural Language API is used and what elements of the query may trigger different types of linguistic understanding. The final article in this series will focus on new ways that Google is adapting search results for each user individually, based on the individuals’ language settings and the software they are using to submit their search, (EX: if the search began in the Google App (![]()

The findings of our research will be especially important to online businesses who appeal to audiences around the world; For them, knowing what search results actually look like for their potential users’ queries, beyond just basic numeric rankings, can be critical for the business success. This is particularly urgent because incorrect Entity Understanding in Google’s new infrastructure might change or limit what searchers can actually see, especially on mobile, when they are traveling or when they are using voice search. Business owners may have to work harder to manage and optimize online marketing channels and SEO, particularly for non-English markets and languages that represent a statistically small portion of overall Google searches.
Jump To:
Word Order Impact on Query Understanding
The order of the words submitted in a search query has not always changed Google’s search results. It only became a factor when they added Phrase Based keyword matching to their English-based algorithm. Now, when word-order is changed, the meaning and intent of the query changes, based on the standard role of word-order in English phrases. In a US-based search for ‘red stoplight’ and ‘stoplight red’, both searches generated image results at the top of the main SERP. In English, the word in position ‘two’ usually describes characteristics of the word on position ‘one’ – generally, it is an adjective then a noun.
The example of this shown below easily illustrates the impact that word-order can have on Google’s results.In the query for ‘red stoplight’ in the screenshot on the left, the words are in the standard order – ‘red’ describes ‘stoplight’. When the order is reversed, to ‘stoplight red,’ as it is in the query on the right, it becomes a query for the color ‘red’ that is as bright as a ‘stoplight’; here, ‘stoplight’ becomes the adjective and ‘red’ becomes the noun (a concept).


Provided by the MobileMoxie Search Simulator
The impact of word order of a query is easy to spot in searches in the US, because it is where Entity Understanding and natural language understanding are the most advanced; but word-order impacts the Query Understanding for any language in which Google has an intermediate level of translation capability.
Language Priority Impact on Translation & Understanding
Next, we wanted to see how Google’s apparent language prioritization impacts their ability to translate, understand and potentially achieve Entity Understanding to generate appropriate Knowledge Graph results. We started by testing the Google Translate API with different languages to see when and how it was more proficient at translation. Since both elements of the Translate API, the Phrase-Based Machine Translation and the Neural Machine Translation, use Machine Learning, they tend to provide more sophisticated translation results for more prolific languages, where they have more ongoing feedback and data to train the system. For languages that have fewer searches and/or a lower priority in Google’s eyes, the Machine Learning part of the translation is less proficient.
The chart below breaks down the relationship of the languages we tested, with The Translate API, The Cloud Natural Language API and Google’s general level of priority in addressing translation in the language. As you can see below, English, Spanish and Hindi are listed as languages of priority, whereas Bulgarian is listed as a low priority language. All tested languages are supported by the Google Translation API and only Spanish and English are included in the Natural Language API. Even though Hindi search results have not always been a strong point for Google, it is listed as a language of priority because of Google ‘Next One Billion Users’ Goal, which we discussed in detail in our precious article: Understanding the Basics of International ASO (1/4).)
Google’s Current Language Understanding
| Language of Priority (Y/N) |
Natural Language API (Y/N) |
|
|---|---|---|
| English | Yes | Yes |
| Spanish | Yes | Yes |
| Hindi | Yes | No |
| Bulgarian | No | No |
Knowing this, we submitted test queries in Spanish, Hindi, and Bulgarian. First, we wanted to find out if Google was using the Phrase-Based Machine Translation (PBMT) & Neural Machine Translation (NMT) models, rather than just translating individual words. Our research focused on testing variations of well-known, language-specific idioms. Since idioms are culturally specific and their meaning does not directly correlate with any word-by word translation, they would never accurately convey meaning without some level of Query Understanding. Similarly, generally has the ability to achieve a basic Query Understanding for phrases and idioms using the Machine Learning aspects of the Translate API.
With this in mind, we figured the translations would give us a clear idea of weather or not Google understood the words in the context of each other with understanding or only individually, one at a time. Experience told us that Google would do a better job with this type of advanced Query Understanding in Google’s top priority languages. Since The Google Translate Utility isolates the The Google Translate API from The Cloud Natural Language API (which are both generally incorporated when you submit a query), the variation between something submitted in Google Translate and something submitted to Google as a search query would be telling. Results taken from this isolated instance of The Translate API clarify how the two APIs are used together to generate the Query Understanding or Entity Understanding in a search result.
We tested two idioms: ‘Break a leg’ and ‘Put yourself in my shoes’. These are good idioms to test because they both say something that no one would really mean literally. Without the locally and linguistically understood meaning of the idiom, the literal meaning of the phrase is confusing, useless or even potentially harmful, (especially with the suggestion that someone ‘break a leg!’) In the same vein, when we say ‘put yourself in my shoes,’ we are not actually requesting anyone wear our shoes, so again, the meaning is lost without deeper linguistic understanding.
With the idiom ‘break a leg’ Google gets it wrong in both Spanish and Bulgarian, but gets it right in Hindi. We think that this might be an indication of the level to which Machine Learning and user engagement factors into the Phrase Based Machine Translation (PBMT) and the Neural Machine Translation (NMT) models from The Translate API. While many people in the world speak Spanish, there are more that speak Hindi. The quantity of users could cause more proficient translation and understanding in Hindi to be available more quickly, simply due to the rate at which feedback is returned and processed for Machine Learning. This would be even more true if potentially, the idiom ‘break a leg’ was commonly queried, translated or searched for in Hindi as compared to Spanish. (Unfortunately, the query volume for these phrases is not high enough that Google Trends could measure and compare the data, so we don’t know this to be true; this is just one potential theory that could explain the data.)
The chart below shows how Google did at translating the idioms:
|
|
Idiom – Google Translate Results | Idiom Meaning in English – Correct Translation |
|||
| English | Idiom: Break a leg! | Meaning: Good Luck! | |||
| Spanish Translation
Leg: pierna |
¡Rompe una pierna! | Google got it WRONG – We saw a direct translation of about injury to a leg. |
|||
| Bulgarian Translation
Leg: крак or krak |
Пречупете крака or Prechupete kraka |
Google got it WRONG – We saw a direct translation of an injury like a threat. |
|||
| Hindi Translation
Leg: पैर or pair |
भाग्य तुम्हारे साथ हो! or bhaagy tumhaare saath ho! |
Google got it RIGHT – Understanding that we are wishing the person ‘luck’ and not any kind of injury. |
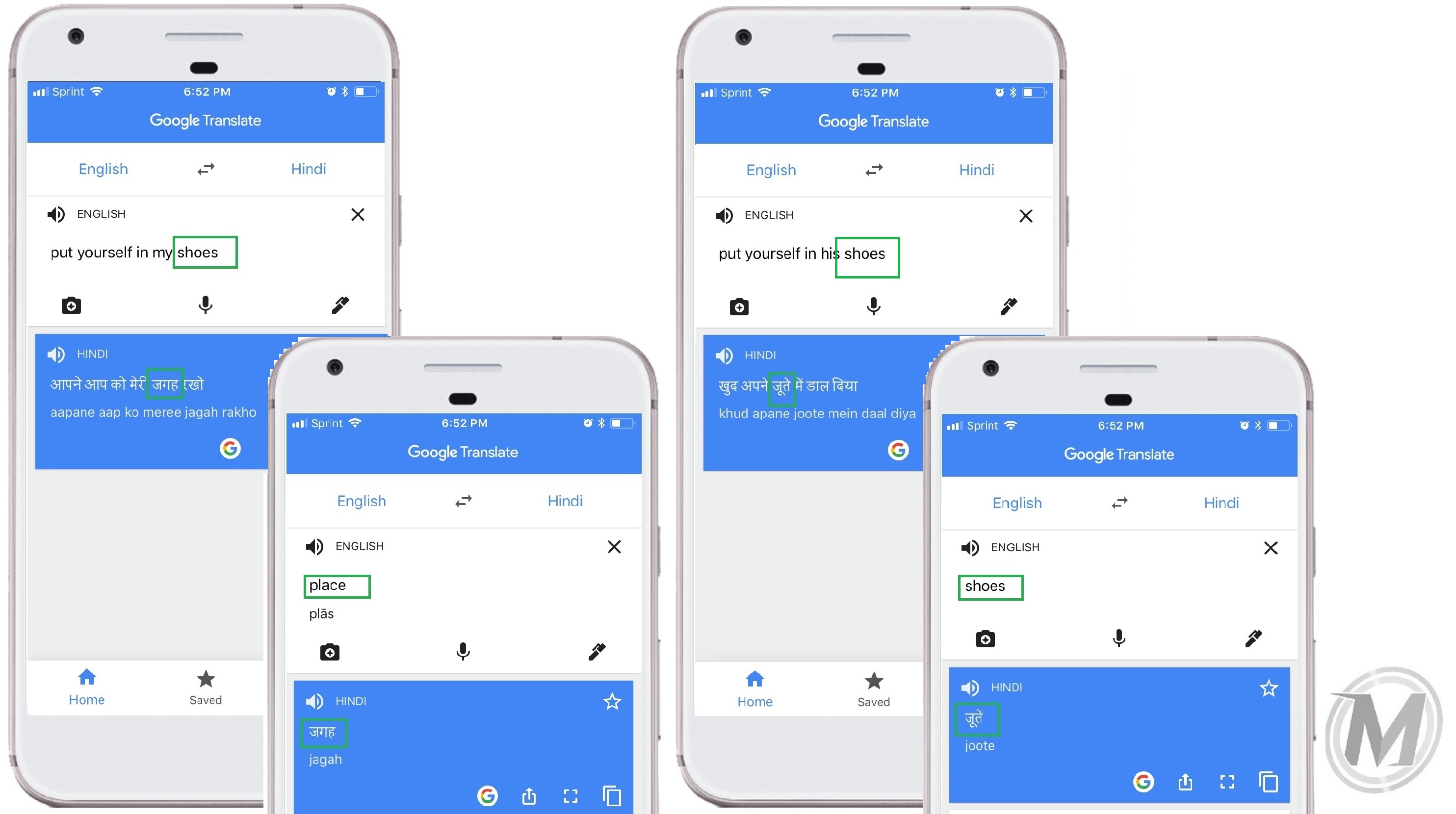
The idiom “Put yourself in his shoes” in Spanish is “Ponte en su lugar,” which literally translates to ‘Put yourself in his place.’ The same phrase in Bulgarian is “Постави се на негово място,” which is also literally translated to ‘Put yourself in his place.’ As shown below, Google Translate translated the idiom from English to Spanish correctly but got it wrong in Bulgarian – what we expected and likely a failing of the quantity of the amount of Machine Learning data in Bulgarian.
To be sure of the validity of the test, we took it a step further and also tested different ownership variations of these idioms, changing the phase, ’Put yourself in MY shoes’ to ‘Put yourself in HIS shoes’. The goal here was to see how deep The Translate API’s mastery of the idiom really went, based on its ability to recognize and correctly interpret both forms (my/his) of the idioms. In this test, the results were the same; Spanish translated correctly but Bulgarian did not, as you can see in the chart below:
| Idiom – Google Translate Results | Idiom Meaning in English – Correct Translation | Idiom Ownership Variation Variation | Idiom Meaning in English – Correct Translation | ||||||
| English | Idiom: Put yourself in MY SHOES | Meaning: Put yourself in MY SITUATION |
Idiom: Put yourself in HIS SHOES | Meaning: >Put yourself in HIS SITUATION | |||||
| Spanish Translation
Shoes: zapatos |
Ponte en mi lugar | Google got it RIGHT – translating ‘shoes’ to ‘place’ or ‘lugar’ |
Ponte en mi lugar | Google got it RIGHT- translating ‘shoes’ to ‘place’ or ‘lugar’ |
|||||
| Hindi Translation
Shoes: जूते or joote |
अपने आप को मेरी जगह रखो | Google got it RIGHT – translating ‘shoes’ to ‘place’ |
खाद अपने जूते में दाल दिया | Google got it WRONG – they did NOT translate ‘shoes’ to ‘place’ |
|||||
| Bulgarian Translation
Shoes: обувки or obuvki |
Постави се в моите обувки |
Google got it WRONG – They did NOT translate ‘shoes’ to ‘place’ or ‘situation’ |
Постави се в неговите обувки | Google got it WRONG – they did NOT translate ‘shoes’ to ‘place |
If you are using Google Translate utility to complete a similar test, be sure to either select ‘English’ or let it default to ‘English-detected.’ Sometimes the tool will translate English words to other languages, even if a different language is selected in the first language ‘from’ field. This is because many languages incorporate English words seamlessly into their vernacular. If the wrong language is selected, you will most likely only be getting the direct dictionary translation of the terms and not the enhanced capabilities required for idioms, probably because there is not enough Machine Learning data for Phrase-Based Machine Translation for the English writing of the words, coming from regions where the non-English languages are spoken. This tells us that Machine Learning for the translation aspect of the API is regionally segmented.
EX: With Korean selected as the ‘from’ language, Google translated ‘Put yourself in my shoes’ incorrectly as ‘Ponte en mis zapatos,’ misunderstanding the idiom, whereas when English is selected, it understood the meaning of the idiom, and translated it correctly to ‘Ponte en mi lugar,’ (Put yourself in my place).

Provided by the MobileMoxie Search Simulator
For languages with low priority, The Cloud Natural Language API is not used at all, so idioms are rarely successfully translated, and if they are, it is because of Machine Learning, through the PBMT and NMT models which are both highly dependent on the volume of in-language user interaction for the particular idiom. Since The Translate API does not provide meaning about the query on its own, variations on idioms are even more rarely translated successfully. We believe that Google rarely understands idioms without support from the Natural Language API and only understands variations on idioms when it is in play or when query volume is high enough that Phrase-Based Machine Translation and Neural Machine Translation may also come into play.
The grid below outlines the predicted levels of Query Understanding you can expect in different languages (with the different level of API support that Google provides each language), according to the research:
| High Priority Language (EX: Spanish/Hindi) | Low Priority Language (EX: Bulgarian) | ||||||||
| Google Translate API – YES Natural Language API – YES |
Google Translate API – YES Natural Language API – NO |
Google Translate API – YES Natural Language API – NO |
Google Translate API – NO Natural Language API – NO |
||||||
| Translate Idioms | Yes | Yes | No | N/A | |||||
| Translate Variations of Idioms | Yes | No | No | N/A | |||||
Translation & Entity Understanding
Since Google can adapt to changes in word order by recognizing phrases, and can recognize and even translate idioms, we wanted to see when and how Google’s Query Understanding changes over to Entity Understanding, especially when language and translation are in-play. Internationally, the impact of word-order is stronger and more meaningful for languages when The Cloud Natural Language API can be used to evaluate the word-order natively without translation, so we made sure to incorporate this into our testing too. To show the varying impact that word order has on search results and Entity Understanding in non-English searches, we set up the the following test:
- We picked two languages that had different language API profiles in Google:
- Spanish – Available in The Cloud Natural Language API and The Translae API – a high priority language
- Bulgarian – Available only in The Translate API, but not in The Cloud Natural Language API – a low priority language
- In each language, we picked two queries to test. The two queries had to convey an entirely different meaning and intent when the word-order was changed. They also had to represent a known Entity when written one way, but not the other:
- Spanish – ‘Amores Perros,’ which translates to ‘Love’s a Bitch’ in English, is a Mexican movie. When the word-order of the movie title is reversed to to be ‘Perros Amores’ it translates to mean ‘sweet/lovable dogs’ because ‘amores’ is the adjective explaining the noun ‘dogs’ or ‘perros’.
- Bulgarian – ‘С Деца на Море’ is an old Bulgarian movie, and the title in English translates to ‘With Kids at the Seaside.’ When you change the order of the movie title, it becomes, ‘На Море с Деца’ which translates in English to be ‘At the Seaside with Kids,’ and reflects a search for a generic vacation plan or concept.
We speculated before testing, that Google would detect the meaning of the Spanish queries in all cases, because it is available in The Cloud Natural Language API, but that Google would struggle in Bulgarian, because it is not supported by The Cloud Natural Language API. You can see below that we were wrong. You can see in the image below that Google serves the movie Knowledge Graph in both versions of the Spanish query. This shows that they are either not detecting the different meanings in the query when the word-order is reversed, or potentially Google is unintentionally ‘algorithmically overfitting‘ the query to the entity. The algorithm may assume that any instance of the words together in a query is a reference to the movie; even when reversing the word-order changes the query meaning entirely.


Provided by the MobileMoxie Search Simulator
It is important to note that this mistake does not happen when the words ‘sweet dogs’ and ‘lovable dogs’ are submitted in English. When submitted in English, the query that triggers a movie query in Spanish, triggers a Knowledge Graph result for the Quite Riot song ‘Love’s a Bitch’ with disambiguation at the top for the Spanish movie entity and the song ‘Love is a Bitch,’ by Two Feet. This confirms that, at least in languages that are supported by The Cloud Natural Language API, that Entity Understanding is either associated with the language or region of the searcher. (Our test searches were submitted from regionally appropriate locations that would naturally be associated with the language of the search – not all submitted from our location in the US. This aspect of testing will grow in importance as Google’s algorithms are able to rapidly evolve, now that Mobile-First Indexing has launched.)


In Bulgarian, Google gets it right, which is a bit unexpected. The Bulgarian movie clearly exists in Google’s Knowledge Graph, so there is Entity Understanding, but the Knowledge Graph result is only triggered when the movie title is written correctly. When the word order is changed, Google does not ‘overfit’ as it did in Spanish, but instead, correctly shows search results that are related to vacation planning – including a high number of paid results. No Knowledge Graph result for the movie.


Provided by the MobileMoxie Search Simulator
This test indicates – at least in this comparison, that Entity Understanding, or what might more accurately be described as Entity Matching, from The Cloud Natural Language API is some how available in Bulgarian even though Bulgarian is not supported by The Cloud Natural Language API. We believe that this may only be possible because when Google detects that a query is being submitted in a language that is not supported by The Cloud Natural Language API, it translates the query to English BEFORE using the API for Entity Matching.
It seems that if there is no exact match the English translation of a query in the Entity Matching functions of The Cloud Natural Language API, Google simply serves local results for the query without Knowledge Graph entities, as shown on the right. You can see that the results in the second Bulgarian query (about a vacation plan) are only in Bulgarian, and it seem to be based on simple keyword matching. It appears that Entity Understanding only comes into play for foreign queries that are not part of The Cloud Natural Language API if there is an exact match to an existing entity in English. If no entity is available that exactly matches the English translation of the query, the algorithm reverts to keyword matching and phrase-based matching to generate search results.
The Cloud Natural Language API is required for their Entity Understanding, even when, (or especially when) comprehensive linguistic understanding is incomplete. Its combination with the Google Translate API makes it possible for the correct Entity Understanding (Knowledge Graph results) to surface for a query, despite not having full understanding of Natural Language for the query.


Provided by the MobileMoxie Search Simulator
The important finding here is that The Cloud Natural Language API is used in all queries; it is used natively for the languages that it supports, and in these cases, can access some degree of Entity Understanding in a ‘broad keyword-match’ approach but risks overfitting the query; for languages that it does not support, it translates the queries to English, and only uses ‘Exact Entity Matching’ to trigger potential Knowledge Graph results. We have included a diagram below to help visualize the process. In any given search query, we can speculate that languages that are supported by The Cloud Natural Language API would follow the path of the yellow line, whereas the process for languages which are not currently supported by The Cloud Natural Language API would follow the path of the blue line:


Manual Translation Feedback
It is important to understand that Google’s linguistic APIs are also being supplemented with user feedback that is accepted within the Google Translate interface and it is admittedly hard to account for the impact that this process could have in our testing, but it is also interesting to think about how it could be used to benefit SEO. Problems in Entity Understanding and Knowledge Graph search rankings for queries may be caused by a mis-translation of the query back to English, especially for languages that are not supported by The Cloud Natural Language API. The manual translation feedback option may give SEO’s strategies to either generate or suppress Knowledge Graph results – especially for languages not supported by The Cloud Natural Language API.
It may be possible to impact Google’s translations by submitting better English translations of the query to Google using the Google Translate feedback utility (app and web both offer this feature.) Volume may be a factor if you attempt to correct something that you perceive as a mistake. We don’t know how Google processes translation feedback – it could be passed through the normal Machine Learning protocols or it could be managed separately, since it is likely received in lower volume. Regardless, manual translation feedback will probably have a stronger impact where there is lower volume of data in the machine learning.
Similarly, SEOs working in non-English languages who want to be trigger or be incorporated into a Knowledge Graph may be able to reverse-into better Entity Understanding and stronger Knowledge Graph search results by choosing to optimize for keywords that already translate correctly into the English. SEO’s who strategically want to avoid triggering or be incorporated into a Knowledge Graph result should use The Cloud Natural Language API tool to ensure that they avoid optimizing for keywords that do not translate correctly to the English keywords that trigger the Knowledge Graph results.
| SEO Wants Knowledge Graph Results: | Cloud Natural Language API Available: | Recommended Strategy: |
|
Yes |
Yes | Ensure keywords are understood natively in The Cloud Natural Language API. If they are not, target keywords that DO correctly trigger the correct Entity Understanding in The Cloud Natural Language API/ trigger Knowledge Graph results in searches. |
| No | If in-language keywords DO NOT translate correctly to English words that trigger the appropriate Entity Understanding in The Cloud Natural Language API/ in Knowledge Graph results in searches, submit manual translation suggestions that help update the translation to match the current Entity Understanding in The Cloud Natural Language API. Target and optimize for words that DO trigger the correct Entity Understanding in The Cloud Natural Language API/ Knowledge Graph results in searches, so that your on-page SEO can help drive traffic for those keywords while you are waiting for the manual translation suggestions to take effect. | |
|
No |
Yes | Target and optimize for variations of your keywords are NOT understood natively in The Cloud Natural Language API, and thus won’t trigger Entity Understanding in The Cloud Natural Language API/ won’t trigger Knowledge Graph results in searches. |
| No | Target and optimize for in-language keywords do not translate correctly to English words that trigger the appropriate Entity Understanding or Knowledge Graph results in searches. Submit manual translation suggestions that distance your in-language keywords from the English Entity Understanding in The Cloud Natural Language API/ Knowledge Graph entities in search results. |
With this approach, it is important to realize that the status of a language could change. Google is working quickly to build-out The Cloud Natural Language API, incorporating more languages as quickly as they can – presumably because it is so important for surfacing correct Knowledge Graph and entity results. In a Google IO session this year, Scott Huffman, Google’s Vice President of Engineering, for the Google Assistant announced that by the end of the year Google Assistant will be available in 30 languages. This may indicate that they are about to include many more languages in The Cloud Natural Language API so this could be an even more important strategy soon.
Conclusion
When considering expanding your business internationally, knowing your audience and their online behavioral patterns is critical for your success. Google’s main goal, in this new way of processing and serving information, is to serve most relevant results by detecting intent through deep linguistic understanding of the search query.When Entity Understanding and search intent are at the center of Google’s indexing of the web, and language and keyword matching is becoming secondary, it represents a fundamental shift in how content will be surfaced moving forward. We feel strongly that in the future of SEO, Entity Understanding will be critical for the fine-tuning a business’ ability to leverage Google’s Mobile-First Indexing across variety of devices, in countries and languages around the world.
In this article, we discussed how and when Google’s two primary Translation APIs play into their ability to leverage Query Understanding and perceive Entity Understanding. Our research indicates that Google seems to have found a somewhat successful way to work around the complexity of language by supporting their machine learning using these two APIs to help with linguistic detection, translation, semantic meaning and Entity Understanding.
It is critical for companies to actively manage mobile, international SEO strategy, to help align online SEO efforts around the world. Being able to reach users with the right information where and when they need it is the goal of any business and seems to be in the core goal of Mobile-First Indexing. The growing potential for cross-device search makes the process of surfacing information even more complex, but Google’s Entity Understanding can help. Previous articles in this series focused on what Entity Understanding is, how Google may have re-indexed the web based on Entity Understanding, and how Entity-First Indexing makes things like language detection and translation more important. In the final article in this series we will outline more of our research related to the impact that query language patterns, physical location and users language preferences, have on search results and Google’s Entity Understanding.