


In the Google Search: State of the Union last May, John Mueller and Martin Splitt spent about a fourth of the address to image-related topics.
They announced a big list of improvements to Google Image Search and predicted that it would be a massive untapped opportunity for SEO.
SEO Clarity, an SEO tool vendor, released a very interesting report around the same time. Among other findings, they found that more than a third of web search results include images.


Images are important to search visitors not only because they are visually more attractive than text, but they also convey context instantly that would require a lot more time when reading text.
Google believes image improvements in search engines will help users more purposely visit pages that match their intentions.
Now, I have some good and bad news for you regarding this new opportunity.
The bad news is that in order to improve your images ranking ability, you need to do the tedious work of adding text metadata in the form of quality alt text and surrounding text.
But, the good news is that we are going to learn how to automate that tedious work with Python!
Here is our plan of action:
- We will use DeepCrawl to crawl a website and find important images that are missing image ALT text.
- We will train a model using Pythia that can generate image captions.
- We will write a Python function to iterate over the images and generate their captions.
- We will learn some tricks to improve the quality of the captions and to produce more personalized ones.
- We will learn about the deep learning concepts that make this possible.
- I will share resources to learn more and interesting community projects.
Introducing Pythia
The advances happening in the deep learning community are both exciting and breathtaking. It is really hard to keep up!
🏎 Smaller, faster, cheaper, lighter: Introducing DilBERT, a distilled version of BERT by @SanhEstPasMoi https://t.co/MuVpaQB4Le
— Hamlet 🇩🇴 (@hamletbatista) August 28, 2019
Just look at the Megatron model released by NVIDIA last month with 8.3 billion parameters and 5 times larger than GPT2, the previous record holder.
But, more importantly, let’s review some of the amazing stuff that is now possible.



Feel free to check out this demo site focused on asking questions about the content of images.
Well, guess what? The framework powering this demo is called Pythia. It is one of the deep learning projects from Facebook and we will be putting it to work in this article.
Extracting Images Missing Alt Text with DeepCrawl



We are going to generate captions for this nice site that has all you can need about alpacas.

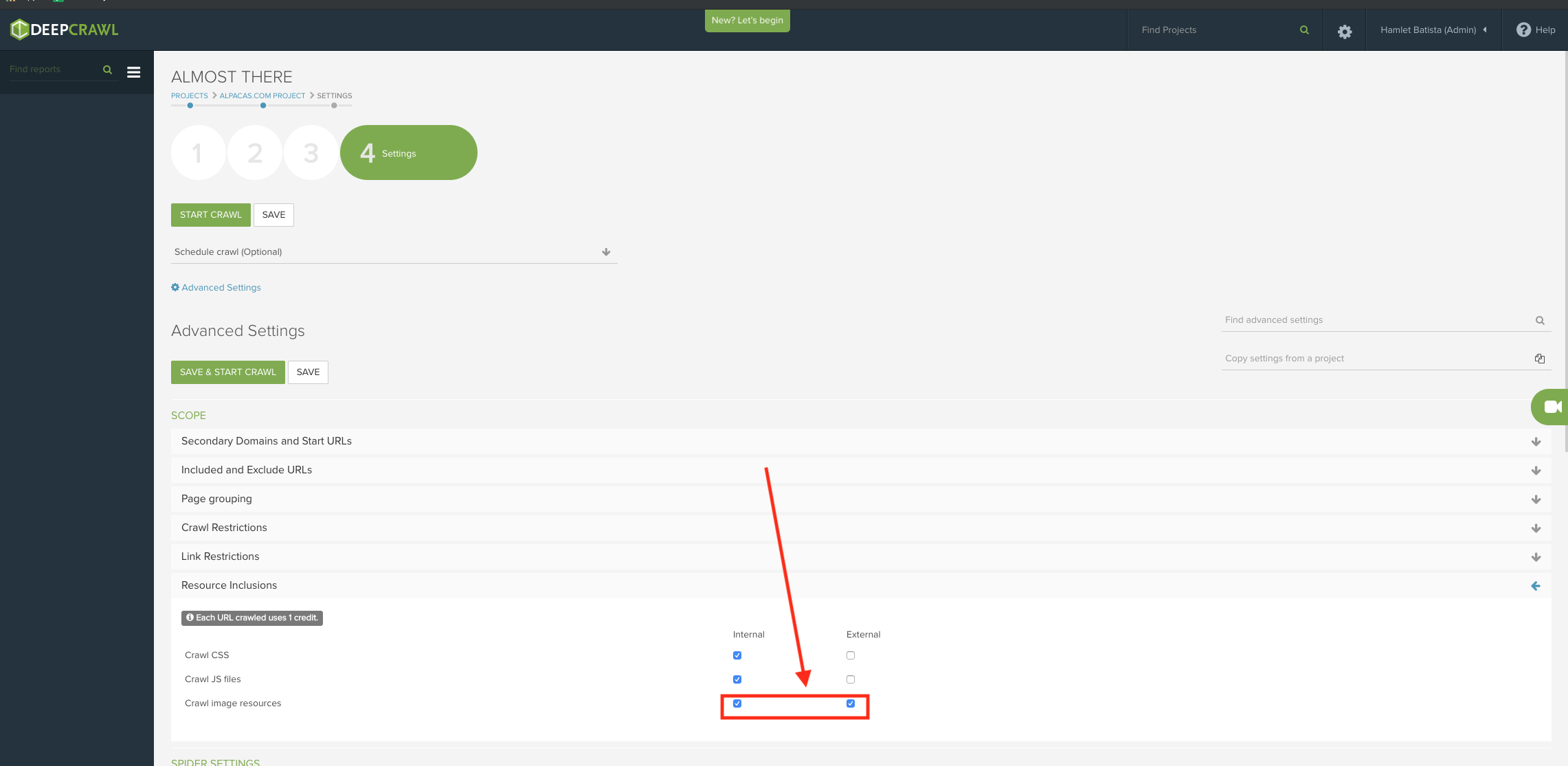

When you set up the crawl, make sure to include image resources (both internal and external).
Select a predefined custom extraction to pull images with no alt text attribute.

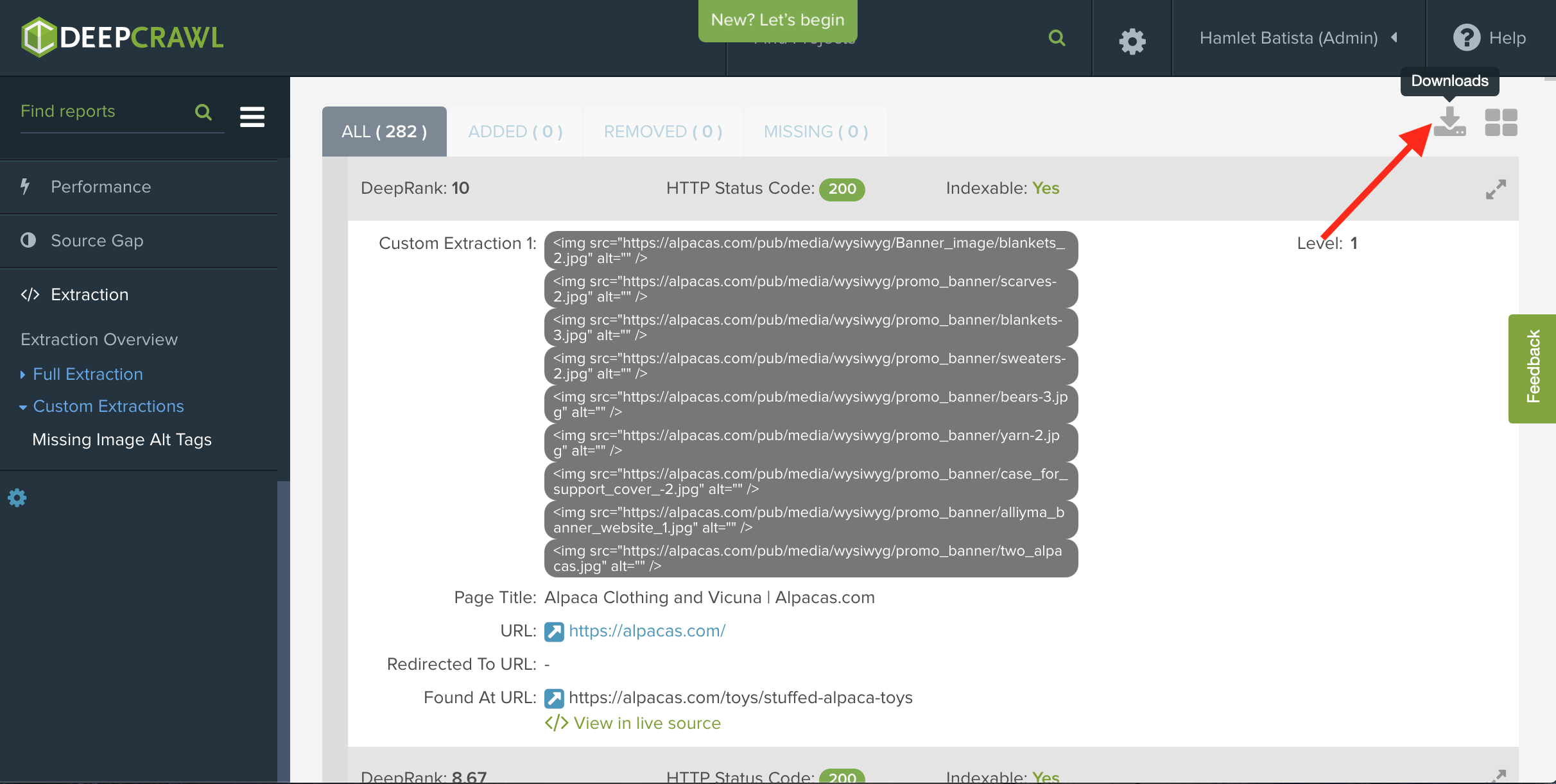

After the crawl finishes, export the list of image URLs as a CSV after the crawl is finished.
Generating Captions from the Images Using Pythia
Head over to the Pythia GitHub page and click on the image captioning demo link. It is labeled “BUTD Image Captioning”.
BUTD stands for “Bottom Up and Top Down”, which is discussed in the research paper that explains the technique used.
Following the link will take you to a Google Colab notebook, but it is read-only. You need to select File > Make a copy in Drive.
Now, the next steps are the hardest part.

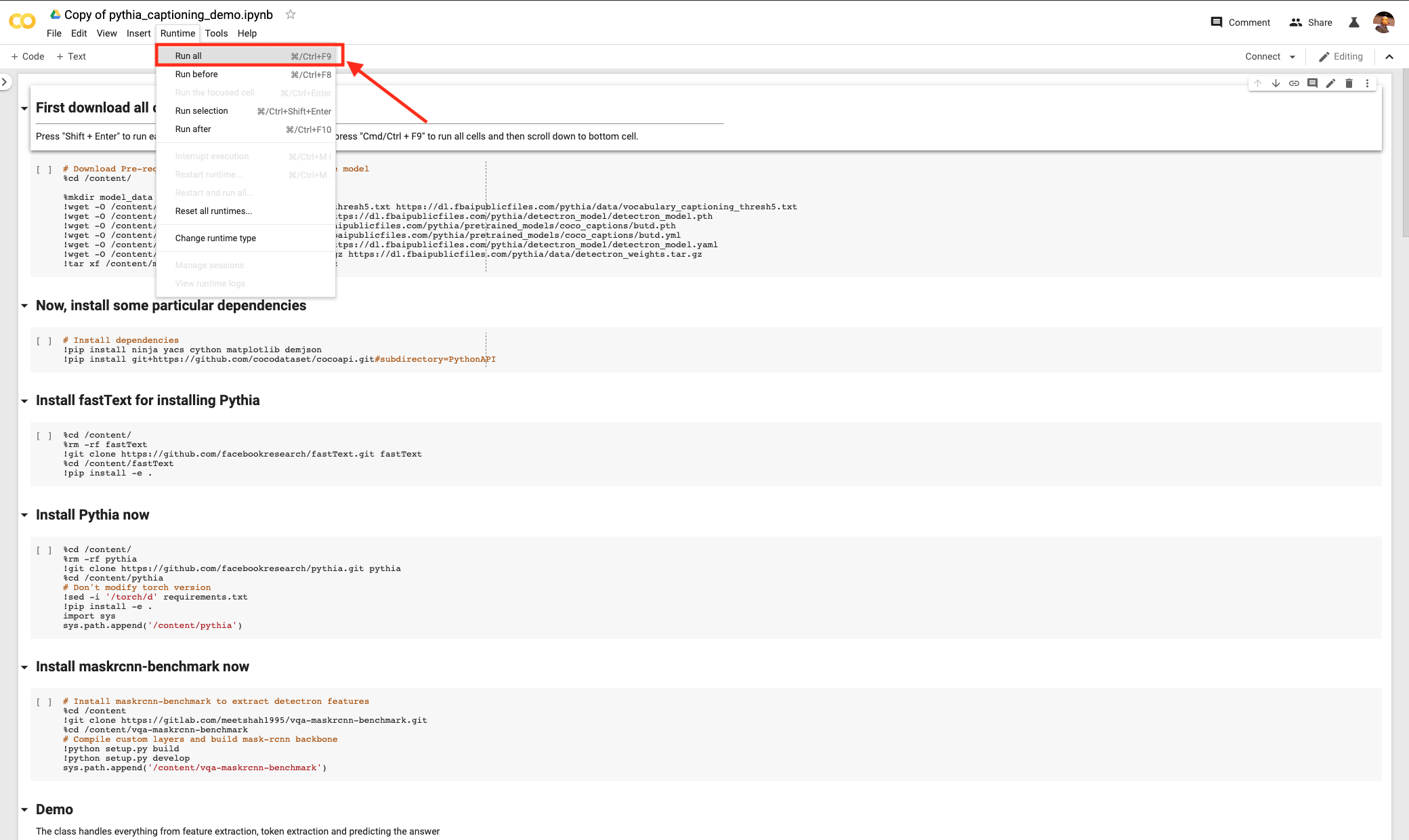

Under Runtime, select Run all.
Scroll down to the last cell in the notebook and wait for the execution to finish.
Copy and paste the example image to a separate cell and run it with Shift+Enter.
image_text = init_widgets(
"http://images.cocodataset.org/train2017/000000505539.jpg"
)
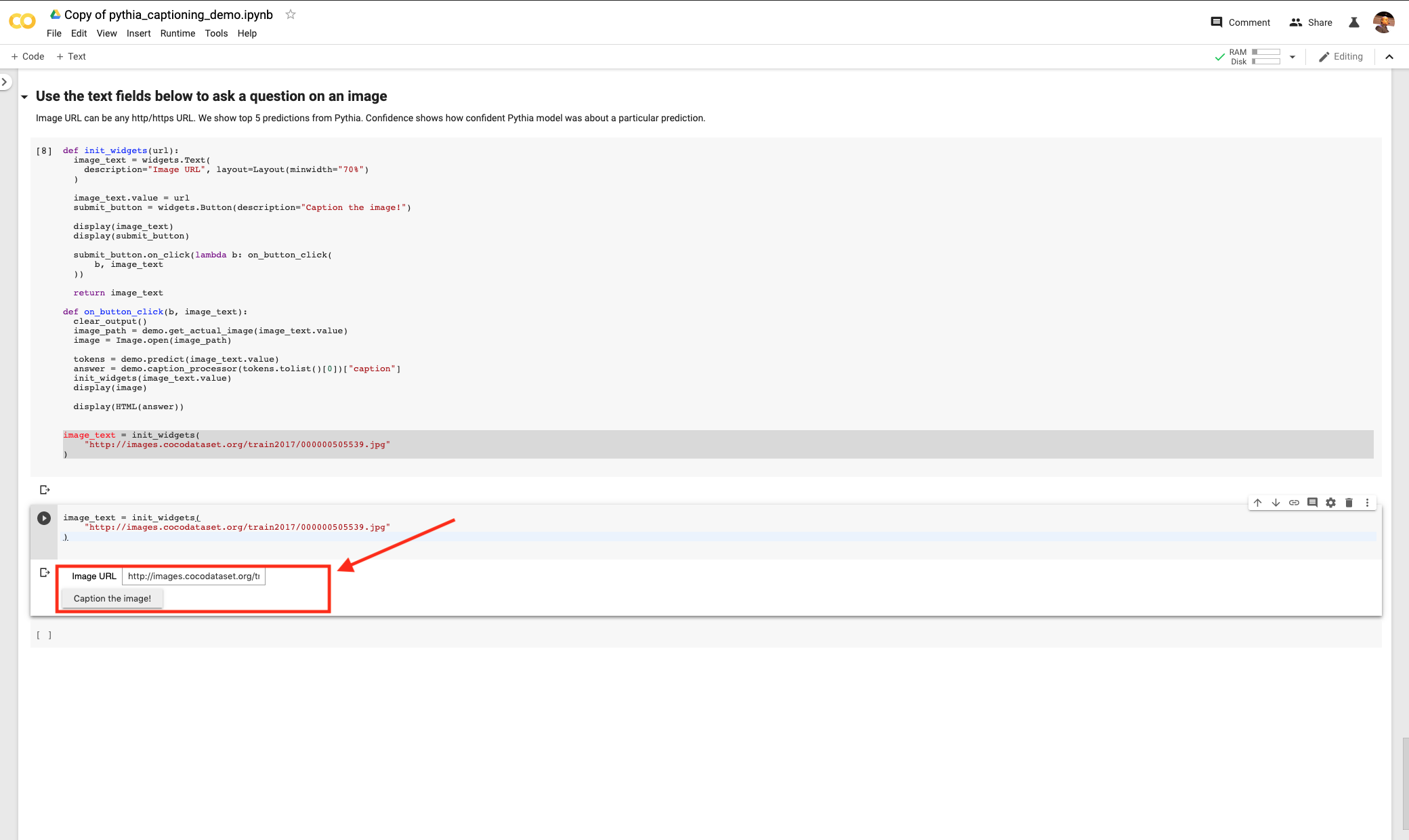
You should see a widget with a prompt to caption an image using its URL. Hit the button that says Caption that image! and you will get this.
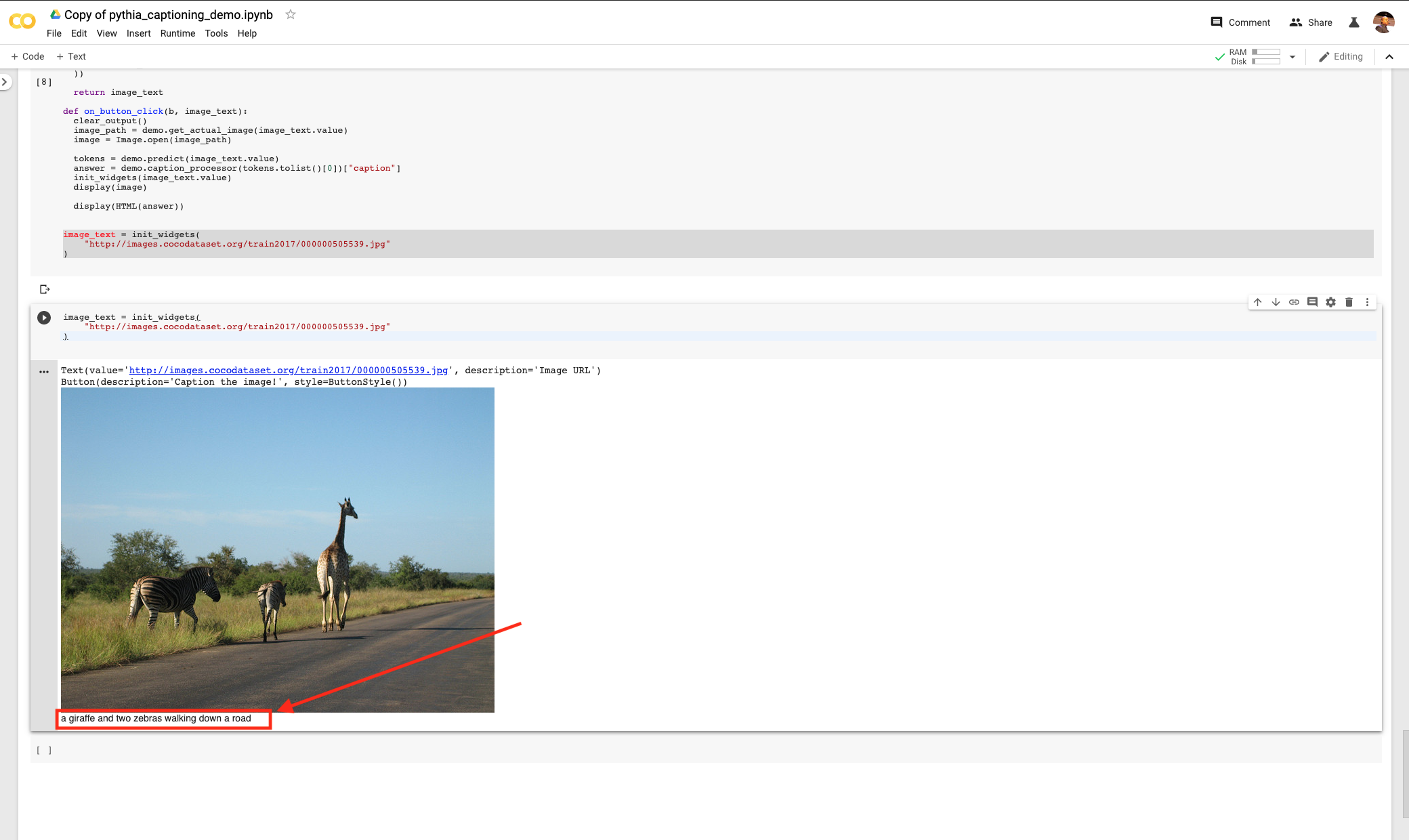
The caption reads clearly “a giraffe and two zebras walking down a road”.
Let’s check a couple of product images missing alt text from our Alpaca Clothing site.
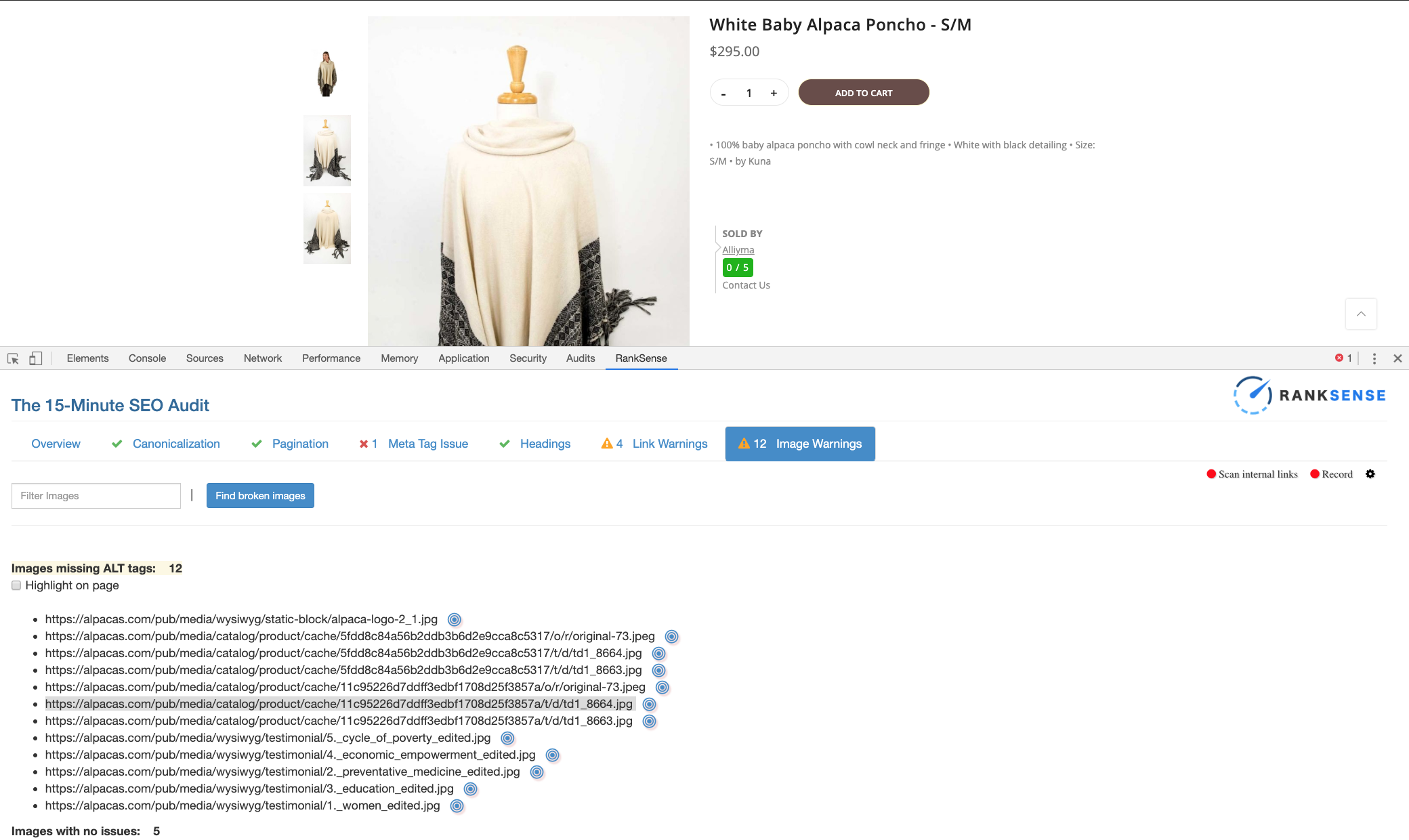
We are reviewing this page specifically.
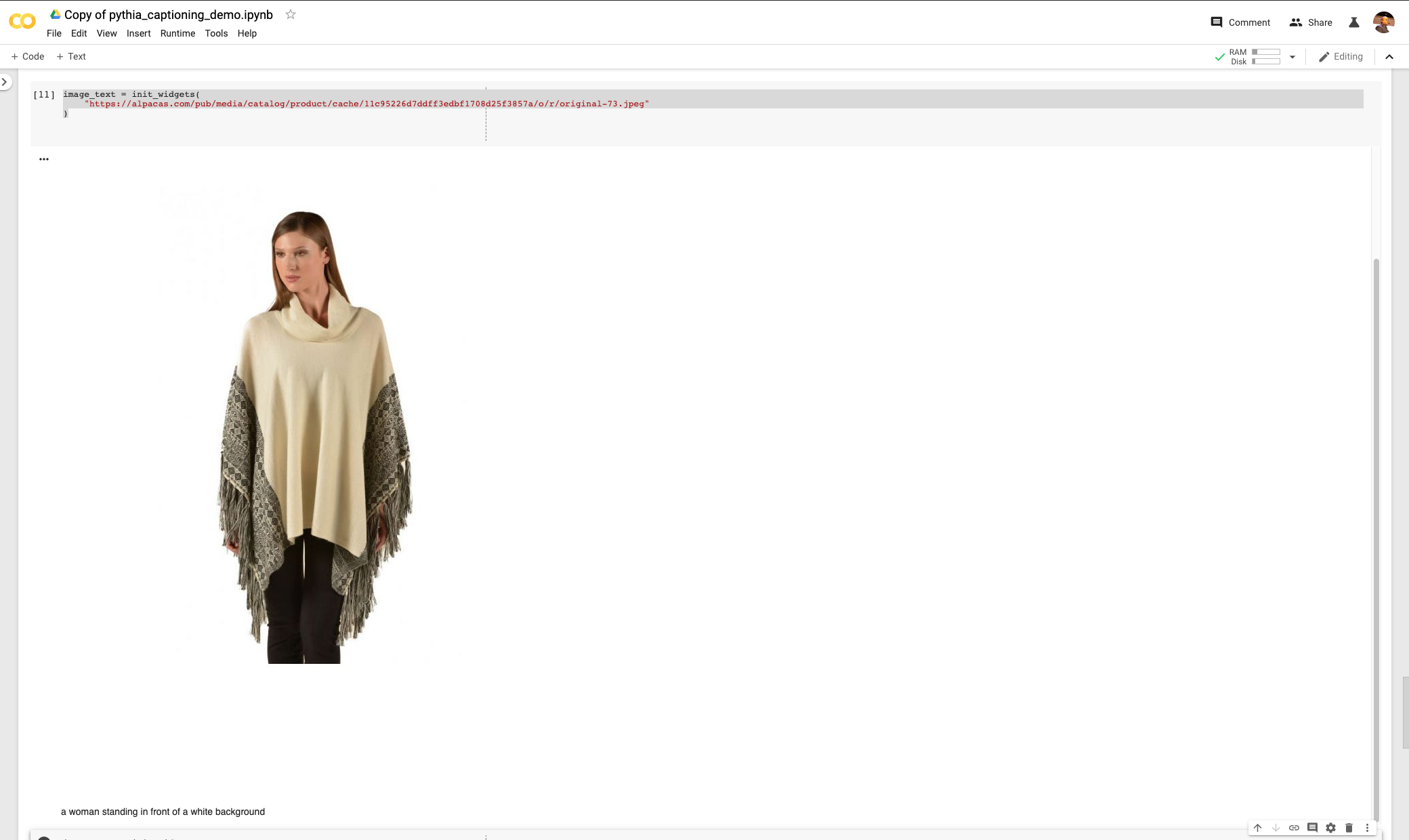
The generated caption reads “a woman standing in front of a white background”.

The generated caption reads “a white vase sitting on top of a table”, which is wrong, but not completely crazy!
Very impressive results without writing a line of code! I was obviously kidding about this being hard at all.
Iterating over All Images Missing Captions with Python
We need to add the following code at the end of the Pythia demo notebook we cloned from their site.
Let’s start by uploading the file we exported from DeepCrawl.
from google.colab import files uploaded = files.upload()
We are going to load the file to pandas to figure out how to extract image URLs using one example URL.
We can make small modifications to the function on_button_click to create our function generate_captions. This function will take the URL of an image as input and output a caption.



Here is one example. The caption reads “a woman in a red dress holding a teddy bear”. It is not 100% accurate, but not terrible either.
This code will help us caption all images for that one example URL.

Here is what the new captions say:
- “a woman smiling with a smile on her face”
- “a pile of vases sitting next to a pile of rocks”
- “a woman smiling while holding a cigarette in her hand”
The examples are close but disappointing. But, the next one was absolutely right!

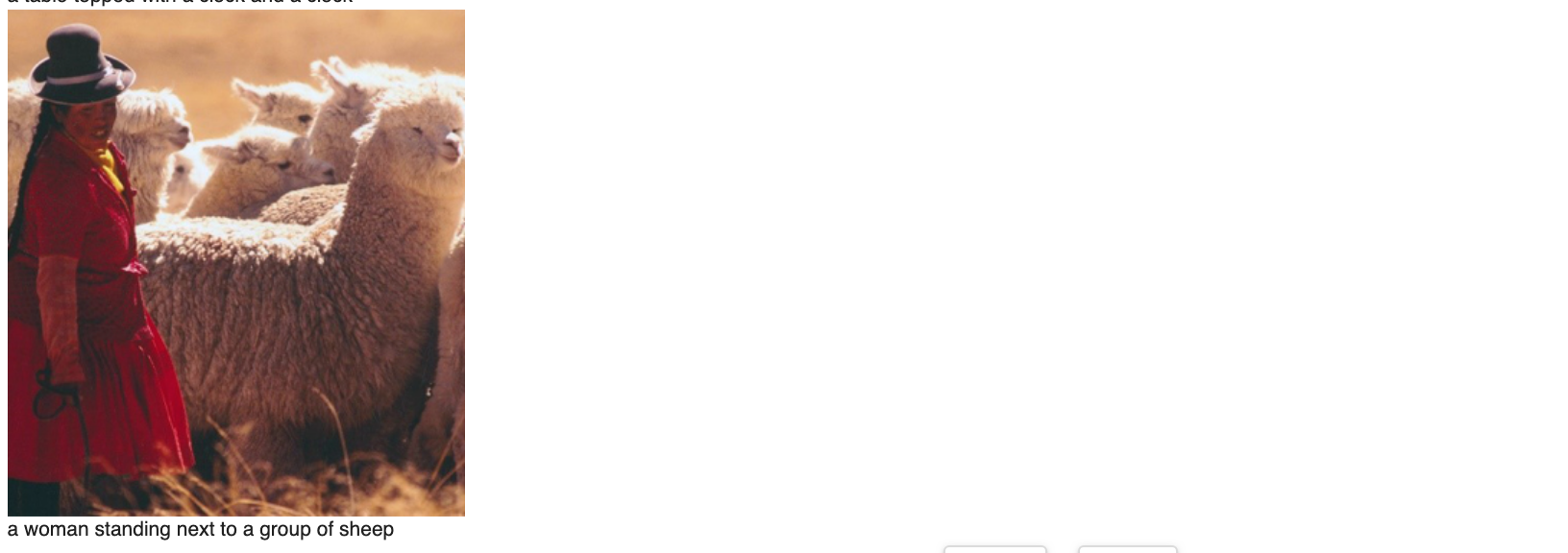
The caption reads “a couple of sheep standing next to each other”, which nobody can argue about, but these are actually alpaca, not sheep.
Finally, let’s make some changes to be able to generate captions for all image URLs we exported from DeepCrawl.
You can see in the output some URLs with extra attributes like this one.
<img style="display: block; margin-left: auto; margin-right: auto;" src="https://www.searchenginejournal.com/https://alpacas.com/pub/media/wysiwyg/panel/shippingusa.jpg" alt="https://www.searchenginejournal.com/" />
The next code snippet will help us remove those extra attributes and get the image URLs.
image_urls = [re.sub('<img .+ src="https://www.searchenginejournal.com/", "https://www.searchenginejournal.com/", url).strip() for url in images if url]
image_urls = [re.sub("https://www.searchenginejournal.com/" alt="https://www.searchenginejournal.com/"s*/>', "https://www.searchenginejournal.com/", url).strip() for url in image_urls if url]
This gives us a clean list with 144 image URLs.
unique_images = set(image_urls)
Next, we turn the list into a set of 44 unique URLs.
Finally, we iterate over every image and generate a caption for it like we did while testing on one URL.
Some images failed to caption due to the size of the image and what the neural network is expecting. I captured, ignored, and reported those exceptions.
Here is what the partial output looks like.





The caption reads “a shelf filled with lots of different colored items”
The captions generated are not particularly accurate because we trained Pythia on a generic captioning dataset. Specifically, the COCO dataset, which stands for Common Objects in Context.
In order to produce better captions, you need to generate your own custom dataset. I will share some ideas and some of my early results in the next section.
The Power of Training on a Custom Dataset
In order to get better captions, you need to build a dataset of images and captions using your own images. The process to do this out of the scope of this article, but here is a tutorial you can follow to get started.
The main idea is that you need to scrape images and ideally five captions per image, resize them to use a standardized size, and format the files as expected by the COCO format.
{
"info": {...},
"licenses": [...],
"images": [...],
"annotations": [...],
"categories": [...], <-- Not in Captions annotations
"segment_info": [...] <-- Only in Panoptic annotations
}
One idea that I’ve successfully used for ecommerce clients is to generate a custom dataset using product images and corresponding five-star review summaries as the captions.
The goal is not just to generate image alt text, but potential benefit-driven headlines.
Let me share some examples when I started playing with this last year. I used 3-5 star reviews to get enough data.






Here are a couple of funny ones to show you that doing this type of work can be a lot of fun. I think I woke up my wife when I bursted laughing at these ones.






Understanding How Pythia Works

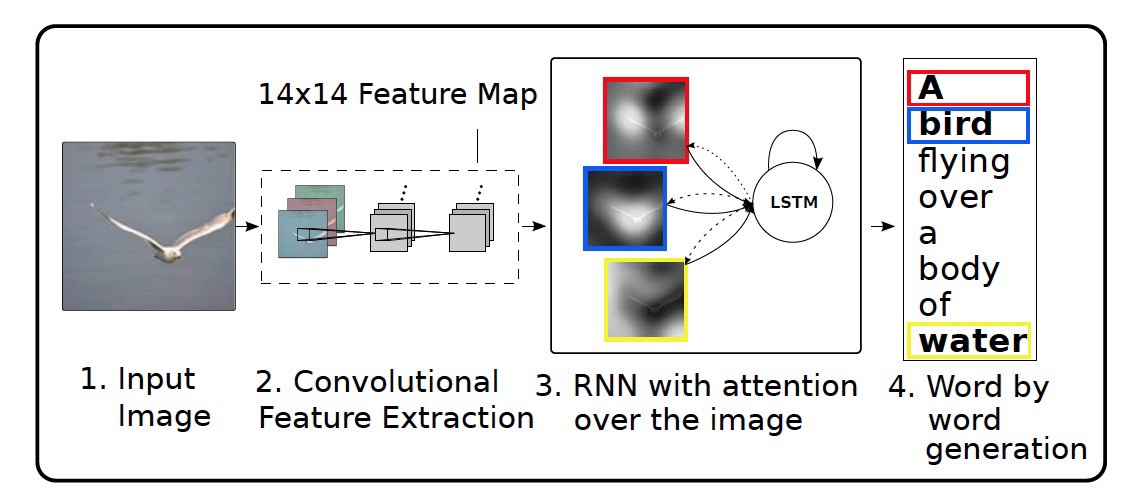

It is very interesting how a neural network produces captions from images.
In my previous deep learning articles, I’ve mentioned the general encoder-decoder approach used in most deep leaning tasks. It is the same with image caption, except that we have two different types of neural networks connected here.
A convolutional neural network takes an image and is able to extract salient features of the image that are later transformed in vectors/embeddings.
A recurrent neural network takes the image embeddings and tries to predict corresponding words that can describe the image.
Pythia uses a more advanced approach which is described in the paper “Bottom Up and Top Down Attention for Image Captioning and Visual Question and Answering”.
Instead of using a traditional CNN which are used in image classification tasks to power the encoder, it uses an object detection neural network (Faster R-CNN) which is able to classify objects inside the images.
I believe this is the main reason that is able to produce high-quality image captions.
Understanding Neural Attention



Neural attention has been one of the most important advances in neural networks.
In simple terms, the attention mechanism allows the network to focus on the right parts of the input that can help complete the transformation task at hand.
In the example above, you can see for example that network associates “playing” with the visual image of the frisbee and the dark background with the fact they are playing in the dark.
Neural attention is a key component of the Transformers architecture that powers BERT and other state-of-the-art encoders.
Resources & Community Projects
I covered this topic of text generation from images and text at length during a recent webinar for DeepCrawl. You can find the recap here and also my answers to attendees’ questions.
I originally learned how to build a captioning system from scratch because it was the final project of the first module of the Advanced Machine Learning Specialization from Coursera.
The classes are incredibly challenging, even more when you are not a full-time machine learning engineer. But, the experience taught me so much about what is possible and the direction the researchers are taking things.
The excitement about Python continues to grow in our community. I see more and more people asking about how to get started and sharing their projects.
First a big shout out to Parker who went to the trouble of getting his company legal team to approve the release of this code he developed internally.
It is a script that reads Stats API data and stores it in a database to help him visualize it in Tableau.
Here are a few more examples and the list keeps growing:
Data collector with custom CTR fitting and score calculation (CTRdelta * Impressions)
Made to track and analyze effect of external links.Build over a GSC wrapper and uses scrapper so you can just enter the external link and a date.https://t.co/5M500uG9kT
— Gefen Hermesh (@Ghermesh) July 31, 2019
Maybe this Content parity report to compare desktop vs mobile for the MFI or for compare sites during migration fits in your article 🙂 https://t.co/zm5KyjYTFQ
— Nacho Mascort (@NachoMascort) July 31, 2019
I didn’t find an easy way to do it in Excel, so here is a way in #python to see competitors that are also ranking for your keywords: https://t.co/u8lJRJY1X9
— Karina Kumykova (@karinakumykova) July 31, 2019
Late, but still 🙂
It’s prepared here:https://t.co/MPb18mG8ay
Readme is still in progress but basic operations are there (I’ll finish it in next hour).
— Filip Podstavec ⛏ (@filippodstavec) September 5, 2019
More Resources:
Image Credits
All screenshots taken by author, September 2019