The most underutilized resources in SEO are search engine results pages (SERPs).
I don’t just mean looking at where our sites rank for a specific keyword or set of keywords, I mean the actual content of the SERPs.
For every keyword you search in Google where you expand the SERP to show 100 results, you’re going to find, on average, around 3,000 words.
That’s a lot of content, and the reason it has the potential to be so valuable to an SEO is that a lot of it has been algorithmically rewritten or cherry-picked from a page by Google to best address what it thinks the needs of the searcher are.
One recent study showed that Google is rewriting or modifying the meta descriptions displayed in the SERPs 92% of the time.
Ask yourself: why would Google want to do that?
It must take a fair amount of resources when it would just be easier to display the custom meta description assigned to a page.
The answer, in my opinion, is that Google only cares about the searcher – not the poor soul charged with writing a new meta description for a page.
Google cares about creating the best search experience today, so people come back and search again tomorrow.
One way it does that is by selecting the parts of a page it wants to appear in a SERP feature or in SERP-displayed metadata that it thinks best match the context or query-intent a person has when they use the search engine.
With that in mind, the ability to analyze the language of the SERPs at scale has the potential to be an incredibly valuable tactic for an SEO, and not just to improve ranking performance.
This kind of approach can help you better understand the needs and desires of potential customers, and it can help you understand the vocabulary likely to resonate with them and related topics they want to engage with.
In this article, you’ll learn some techniques you can use to do this at scale.
Be warned, these techniques are dependent on Python – but I hope to show this is nothing to be afraid of. In fact, it’s the perfect opportunity to try and learn it.
Don’t Fear Python
I am not a developer, and have no coding background beyond some basic HTML and CSS. I have picked Python up relatively recently, and for that, I have Robin Lord from Distilled to thank.
I cannot recommend enough that you check out his slides on Python and his extremely useful and easily accessible guide on using Jupyter Notebooks – all contained in this handy Dropbox.
For me, Python was something that always seemed difficult to comprehend – I didn’t know where the scripts I was trying to use were going, what was working, what wasn’t and what output I should expect.
If you’re in that situation, read Lord’s guide. It will help you realize that it doesn’t need to be that way and that working with Python in a Jupyter Notebook is actually more straightforward than you might think.
It will also put each technique referenced in this article easily within reach, and give you a platform to conduct your own research and set up some powerful Python automation of your own.
Getting Your SERP Data
As an employee, I’m lucky to have access to Conductor where we can run SERP reports, which use an external API to pull SERP-displayed metadata for a set of keywords.
This is a straightforward way of getting the data we need in a nice clean format we can work with.
It looks like this:

Another way to get this information at scale is to use a custom extraction on the SERPs with a tool like Screaming Frog or DeepCrawl.
I have written about how to do this, but be warned: it is maybe just a tiny little insignificant bit in violation of Google’s terms of service, so do it at your own peril (but remember, proxies are the perfect antidote to this peril).
Alternatively, if you are a fan of irony and think it’s a touch rich that Google says you can’t scrape its content to offer your users a better service, then please, by all means, deploy this technique with glee.
If you aren’t comfortable with this approach, there are also many APIs that are pretty cost-effective, easy to use and provide the SERP data you need to run this kind of analysis.
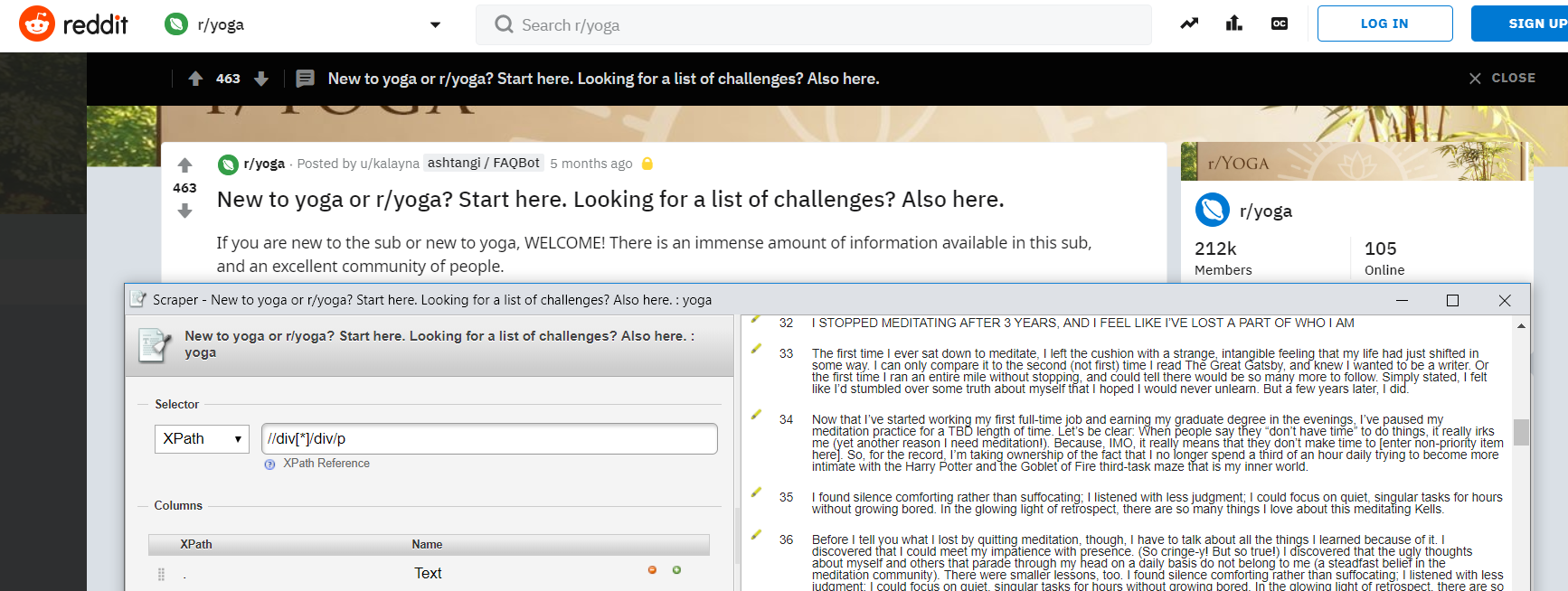
The final method of getting the SERP data in a clean format is slightly more time-consuming, and you’re going to need to use the Scraper Chrome extension and do it manually for each keyword.
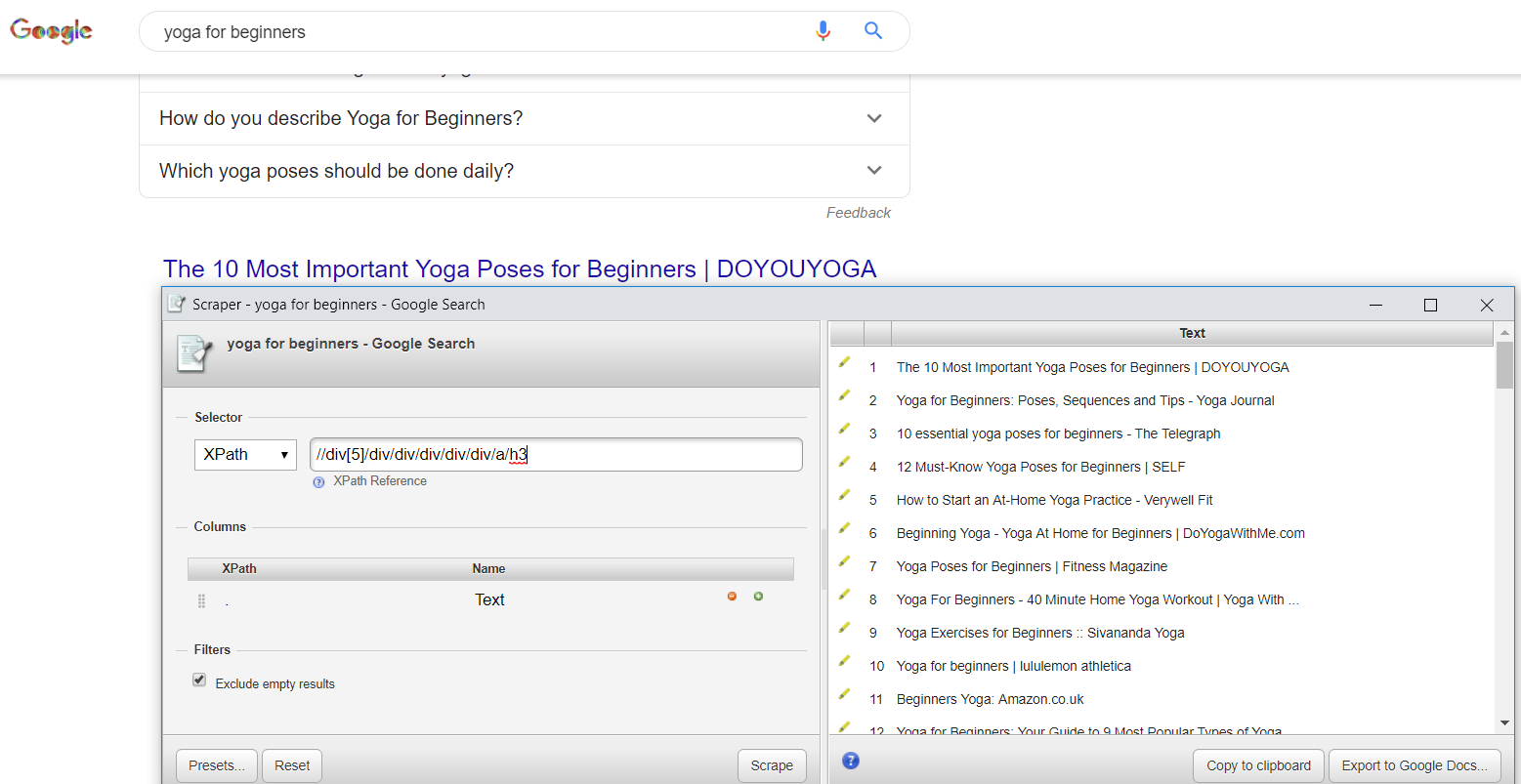
If you’re really going to scale this up and want to work with a reasonably large corpus (a term I’m going to use a lot – it’s just a fancy way of saying a lot of words) to perform your analysis, this final option probably isn’t going to work.
However, if you’re interested in the concept and want to run some smaller tests to make sure the output is valuable and applicable to your own campaigns, I’d say it’s perfectly fine.
Hopefully, at this stage, you’re ready and willing to take the plunge with Python using a Jupyter Notebook, and you’ve got some nicely formatted SERP data to work with.
Let’s get to the interesting stuff.
SERP Data & Linguistic Analysis
As I’ve mentioned above, I’m not a developer, coding expert, or computer scientist.
What I am is someone interested in words, language, and linguistic analysis (the cynics out there might call me a failed journalist trying to scratch out a living in SEO and digital marketing).
That’s why I’ve become fascinated with how real data scientists are using Python, NLP, and NLU to do this type of research.
Put simply, all I’m doing here is leveraging tried and tested methods for linguistic analysis and finding a way to apply them in a way that is relevant to SEO.
For the majority of this article, I’ll be talking about the SERPs, but as I’ll explain at the end, this is just scratching the surface of what is possible (and that’s what makes this so exciting!).
Cleaning Text for Analysis
At this point, I should point out that a very important prerequisite of this type of analysis is ‘clean text’. This type of ‘pre-processing’ is essential in ensuring you get a good quality set of results.
While there are lots of great resources out there about preparing text for analysis, for the sake of levity, you can assume that my text has been through most or all of the below processes:
- Lower case: The methods I mention below are case sensitive, so making all the copy we use lower case will avoid duplication (if you didn’t do this, ‘yoga’ and ‘Yoga’ would be treated as two different words)
- Remove punctuation: Punctuation doesn’t add any extra information for this type of analysis, so we’ll need to remove it from our corpus
- Remove stop words: ‘Stop words’ are commonly occurring words within a corpus that add no value to our analysis. In the examples below, I’ll be using predefined libraries from the excellent NLTK or spaCy packages to remove stop words.
- Spelling correction: If you’re worried about incorrect spellings skewing your data, you can use a Python library like TextBlob that offers spelling correction
- Tokenization: This process will convert our corpus into a series of words. For example, this:
([‘This is a sentence’])
will become:
([‘this’, ‘is’, ‘a’, ‘sentence’])
- Stemming: This refers to removing suffixes like ‘-ing’, ‘-ly’ etc. from words and is totally optional
- Lemmatization: Similar to ‘stemming,’ but rather than just removing the suffix for a word, lemmatization will convert a word to its root (e.g. “playing” becomes “play”). Lemmatization is often preferred to stemming.
This might all sound a bit complicated, but don’t let it dissuade you from pursuing this type of research.
I’ll be linking out to resources throughout this article which break down exactly how you apply these processes to your corpus.
NGram Analysis & Co-Occurrence
This first and most simple approach that we can apply to our SERP content is an analysis of nGram co-occurrence. This means we’re counting the number of times a word or combination of words appears within our corpus.
Why is this useful?
Analyzing our SERPs for co-occurring sequences of words can provide a snapshot of what words or phrases Google deems most relevant to the set of keywords we are analyzing.
For example, to create the corpus I’ll be using through this post, I have pulled the top 100 results for 100 keywords around yoga
This is just for illustrative purposes; if I was doing this exercise with more quality control, the structure of this corpus might look slightly different.
All I’m going to use now is the Python counter function, which is going to look for the most commonly occurring combinations of two- and three-word phrases in my corpus.
The output looks like this:
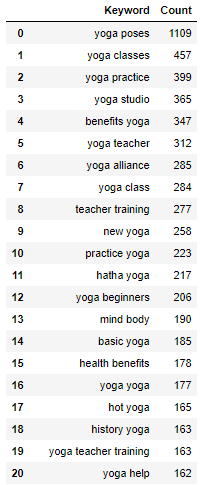
You can already start to see some interesting trends appearing around topics that searchers might be interested in. I could also collect MSV for some of these phrases that I could target as additional campaign keywords.
At this point, you might think that it’s obvious all these co-occurring phrases contain the word yoga as that is the main focus of my dataset.
This would be an astute observation – it’s known as a ‘corpus-specific stopword’, and because I’m working with Python it’s simple to create either a filter or a function that can remove those words.
My output then becomes this:
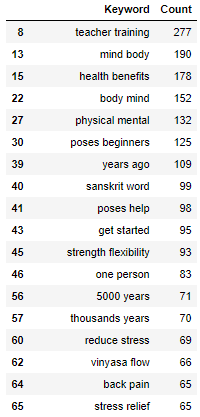
These two examples can help provide a snapshot of the topics that competitors are covering on their landing pages.
For example, if you wanted to demonstrate content gaps in your landing pages against your top performing competitors, you could use a table like this to illustrate these recurring themes.
Incorporating them is going to make your landing pages more comprehensive, and will create a better user experience.
The best tutorial that I’ve found for creating a counter like the one I’ve used above can be found in the example Jupyter Notebook that Robin Lord has put together (the same one linked to above). It will take you through exactly what you need to do, with examples, to create a table like the one you can see above.
That’s pretty basic though, and isn’t always going to give you results that are actionable.
So what other types of useful analysis can we run?
Part of Speech (PoS) Tagging & Analysis
PoS tagging is defined as:
“In corpus linguistics, Part-Of-Speech Tagging (POS tagging or POST), also called grammatical tagging, is the process of marking up a word in a text (corpus) as corresponding to a particular part of speech, based on both its definition, as well as its context—i.e. relationship with adjacent and related words in a phrase, sentence, or paragraph.”
What this means is that we can assign every word in our SERP corpus a PoS tag based not only on the definition of the word, but also the context with which it appears in a SERP-displayed meta description or page title.
This is powerful, because what it means is that we can drill down into specific PoS categories (verbs, nouns, adjectives etc.), and this can provide valuable insights around how the language of the SERPs is constructed.
Side note – In this example, I am using the NLTK package for PoS tagging. Unfortunately, PoS tagging in NLTK isn’t available in many languages.
If you are interested in pursuing this technique for languages other than English, I recommend looking at TreeTagger, which offers this functionality across a number of different languages.
Using our SERP content (remembering it has been ‘pre-processed’ using some of the methods mentioned earlier in the post) for PoS tagging, we can expect an output like this in our Jupyter Notebook:
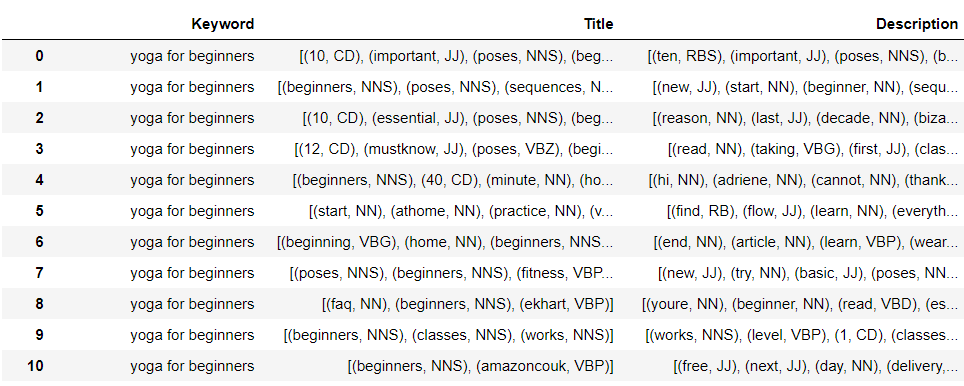
You can see each word now has a PoS tag assigned to it. Click here for a glossary of what each of the PoS tags you’ll see stands for.
In isolation, this isn’t particularly useful, so let’s create some visualizations (don’t worry if it seems like I’m jumping ahead here, I’ll link to a guide at the end of this section which shows exactly how to do this) and drill into the results:
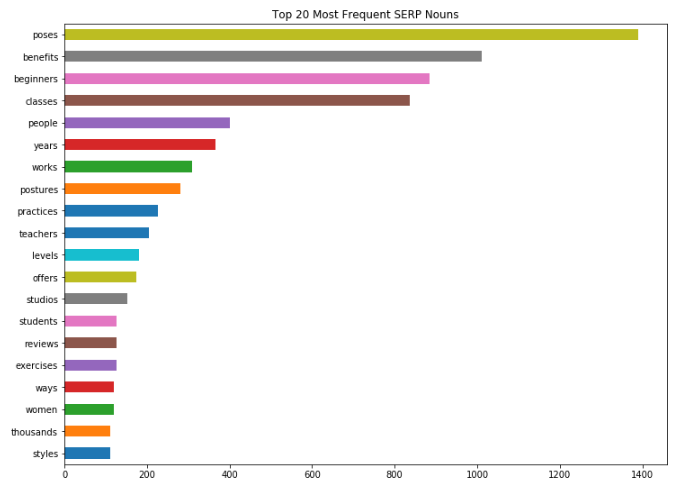
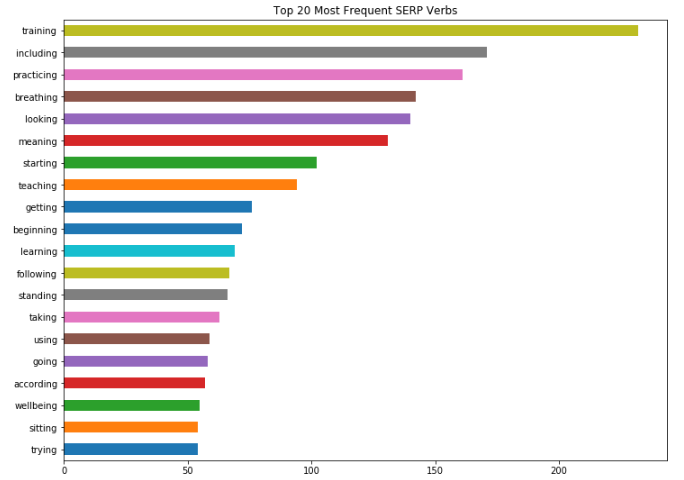
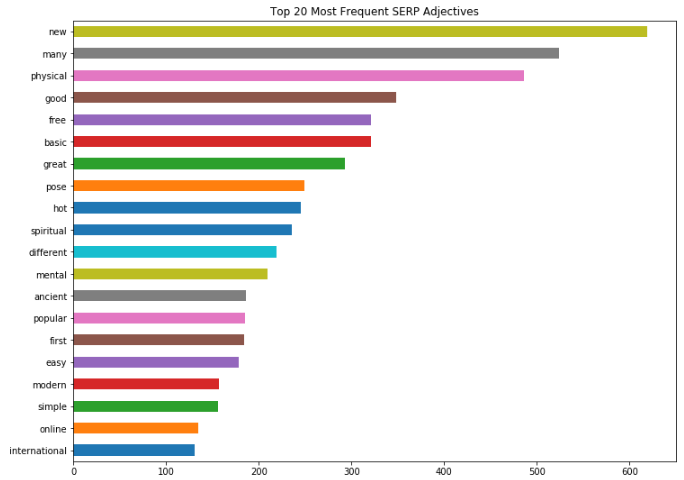
Great!
I can quickly and easily identify the linguistic trends across my SERPs and I can start to factor that into the approach I take when I optimize landing pages for those terms.
This means that I’m not only going to optimize for the query term by including it a certain number of times on a page (thinking beyond that old school keyword density mindset).
Instead, I’m going to target the context and intent that Google seems to favor based on the clues it’s giving me through the language used in the SERPs.
In this case, those clues are the most commonly occurring nouns, verbs, and adjectives across the results pages.
We know, based on patents Google has around phrase-based indexing, that it has the potential to use “related phrases” as a factor when it is ranking pages.
These are likely to consist of semantically relevant phrases that co-occur on top performing landing pages and help crystalize the meaning of those pages to the search engines.
This type of research might give us some insight into what those related phrases could be, so factoring them into landing pages has the potential to be valuable.
Now, to make all this SERP content really actionable, your analysis needs to be more targeted.
Well, the great thing about developing your own script for this analysis is that it’s really easy to apply filters and segment your data.
For example, with a few keystrokes I can generate an output that will compare Page 1 trends vs. Page 2:
Page 1:
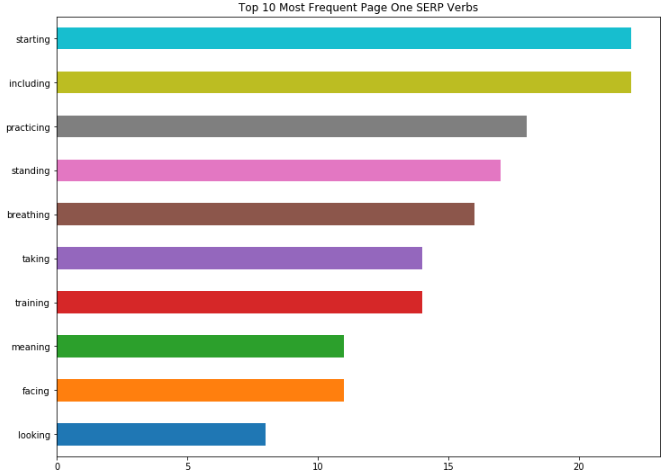
Page 2:
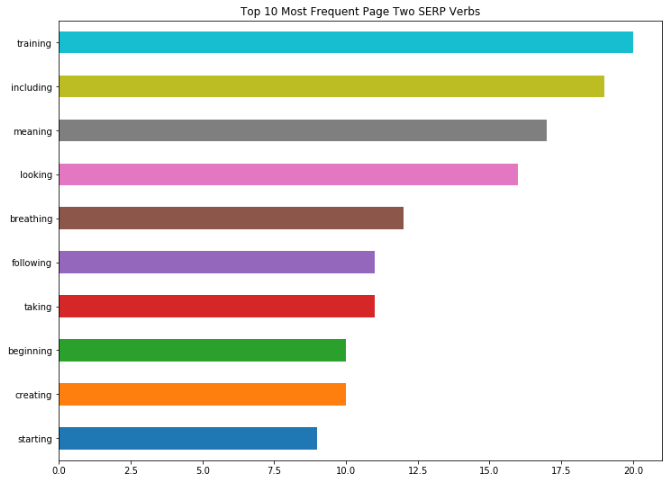
If there are any obvious differences between what I see on Page 1 of the results versus Page 2 (for example “starting” being the most common verb on Page 1 vs “training” on Page 2), then I will drill into this further.
These could be the types of words that I place more emphasis on during on page optimization to give the search engines clearer signals about the context of my landing page and how it matches query-intent.
I can now start to build a picture of what type of language Google chooses to display in the SERPs for the top ranking results across my target vertical.
I can also use this as a hint as to the type of vocabulary that will resonate with searchers looking for my products or services, and incorporate some of those terms into my landing pages accordingly.
I can also categorize my keywords based on structure, intent, or a stage in the buying journey and run the same analysis to compare trends to make my actions more specific to the results I want to achieve.
For example, trends between yoga keywords modified with the word “beginner” versus those that are modified with the word “advanced”.
This will give me more clues about what Google thinks is important to searchers looking for those types of terms, and how I might be able to better optimize for those terms.
If you want to run this kind of analysis for your SERP data, follow this simple walkthrough by Kaggle based on applying PoS tagging to movie titles. It walks you through the process I’ve gone through to create the visuals used in the screenshots above.
Topic Modeling Based on SERP Data
Topic modeling is another really useful technique that can be deployed for our SERP analysis. What it refers to is a process of extracting topics hidden in a corpus of text; in our case the SERPs, for our set of target keywords.
While there are a number of different techniques for topic modeling, the one that seems favored by data scientists is LDA (Latent Dirichlet Allocation), so that is the one I chose to work with.
A great explanation of how LDA for topic modeling works comes from the Analytics Vidhya blog:
“LDA assumes documents are produced from a mixture of topics. Those topics then generate words based on their probability distribution. Given a dataset of documents, LDA backtracks and tries to figure out what topics would create those documents in the first place.”
Although our keywords are all about ‘yoga’, the LDA mechanism we use assumes that within that corpus there will be a set of other topics.
We can also use the Jupyter Notebook interface to create interactive visuals of these topics and the “keywords” they are built from.
The reason that topic modeling from our SERP corpus can be so valuable to an SEO, content marketer or digital marketer is that the topics are being constructed based on what Google thinks is most relevant to a searcher in our target vertical (remember, Google algorithmically rewrites the SERPs).
With our SERP content corpus, let’s take a look at the output for our yoga keyword (visualized using the PyLDAvis package):
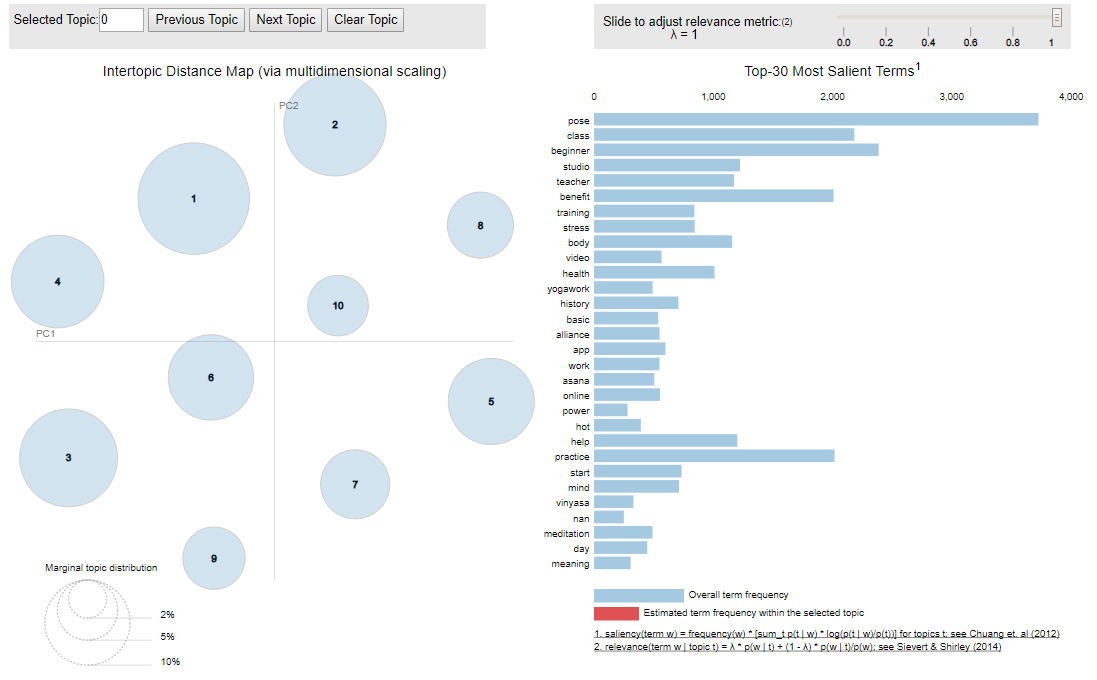
You can find a thorough definition of how this visualization is computed here.
To summarize, in my own painfully unscientific way, the circles represent the different topics found within the corpus (based on clever machine learning voodoo). The further away the circles are, the more distinct those topics are from one another.
The list of terms in the right of the visualization are the words that create these topics. These words are what I use to understand the main topic, and the part of the visualization that has real value.
In the video below, I’ll show you how I can interact with this visual:
At a glance, we’ll be able to see what subtopics Google thinks searchers are most interested in. This can become another important data point for content ideation, and the list of terms the topics are built from can be used for topical on-page optimization.
The data here can also have applications in optimizing content recommendations across a site and internal linking.
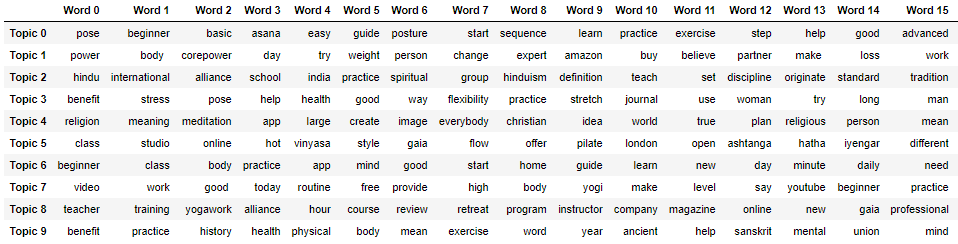
For example, if we are creating content around ‘topic cluster 4’ and we have an article about the best beginner yoga poses, we know that someone reading that article might also be interested in a guide to improving posture with yoga.
This is because ‘topic cluster 4’ is comprised of words like this:
- Pose
- Beginner
- Basic
- Asana
- Easy
- Guide
- Posture
- Start
- Learn
- Practice
- Exercise
I can also export the list of associated terms for my topics in an Excel format, so it’s easy to share with other teams that might find the insights helpful (your content team, for example):
Ultimately, topics are characteristic of the corpus we’re analyzing. Although there’s some debate around the practical application of topic modeling, building a better understanding of the characteristics of the SERPs we’re targeting will help us better optimize for them. That is valuable.
One last point on this, LDA doesn’t label the topics it creates – that’s down to us – so how applicable this research is to our SEO or content campaigns is dependent on how distinct and clear our topics are.
The screenshot above is what a good topic cluster map will look like, but what you want to avoid is something that looks like the next screenshot. The overlapping circles tell us the topics aren’t distinct enough:
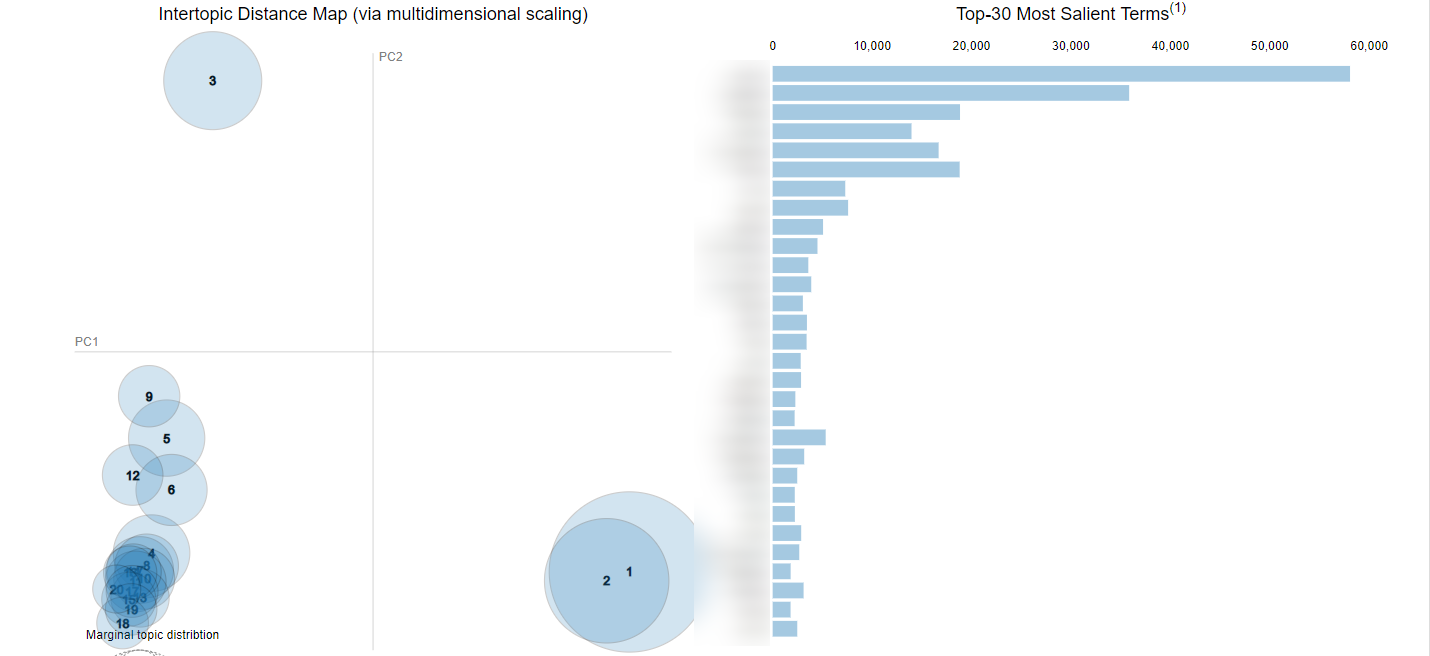
You can avoid this by making sure the quality of your corpus is good (i.e. remove stop words, lemmatization, etc.), and by researching how to train your LDA model to identify the ‘cleanest’ topic clusters based on your corpus.
Interested in applying topic modeling to your research? Here is a great tutorial taking you through the entire process.
What Else Can You Do With This Analysis?
While there are some tools already out there that use these kinds of techniques to improve on-page SEO performance, support content teams and provide user insights, I’m an advocate for developing your own scripts/tools.
Why? Because you have more control over the input and output (i.e., you aren’t just popping a keyword into a search bar and taking the results at face value).
With scripts like this you can be more selective with the corpus you use and the results it produces by applying filters to your PoS analysis, or refining your topic modeling approach, for example.
The more important reason is that it allows you to create something that has more than one useful application.
For example, I can create a new corpus out of sub-Reddit comments for the topic or vertical I’m researching.
Doing PoS analysis or topic modeling on a dataset like that can be truly insightful for understanding the language of potential customers or what is likely to resonate with them.
The most obvious alternative use case for this kind of analysis is to create your corpus from content on the top ranking pages, rather than the SERPs themselves.
Again, the likes of Screaming Frog and DeepCrawl make it relatively simple to extract copy from a landing page.
This content can be merged and used as your corpus to gather insights on co-occurring terms and the on-page content structure of top performing landing pages.
If you start to work with some of these techniques for yourself, I’d also suggest you research how to apply a layer of sentiment analysis. This would allow you to look for trends in words with a positive sentiment versus those with a negative sentiment – this can be a useful filter.
I hope this article has given you some inspiration for analyzing the language of the SERPs.
You can get some great insights on:
- What types of content might resonate with your target audience.
- How you can better structure your on-page optimization to account for more than just the query term, but also context and intent.
More Resources:
Image Credits
Featured Image: Unsplash
All screenshots taken by author, June 2019