
Web scraping is one of the best tools for competitive content analysis. It allows to automate data collection and get the deepest insight into competitors’ content
What do you usually do when you want to purchase something or learn a new skill? You take your smartphone or laptop and search for reviews and how-tos trying to find content that will satisfy your intent. Fortunately, there are tonnes of content available nowadays.

Download our Individual Member Resource – Competitor benchmarking guide
Benchmarking is vital when you’re refreshing a website through a major redesign, but it can also be useful to review more regularly to see how competitors’ marketing changes.
Access the Competitor benchmarking guide
Things get more complicated when you are on the other side. If you are a startup that wants to launch a content marketing campaign, you may realize that the market is quite saturated (not to say overwhelmed).
According to the B2B Content Marketing 2019 Research by the Content Marketing Institute and MarketingProfs, 93% of the most successful B2B content marketers report their organization is extremely/very committed to content marketing. What’s more, 70% of content marketers say that their content marketing advances and becomes more successful each year.
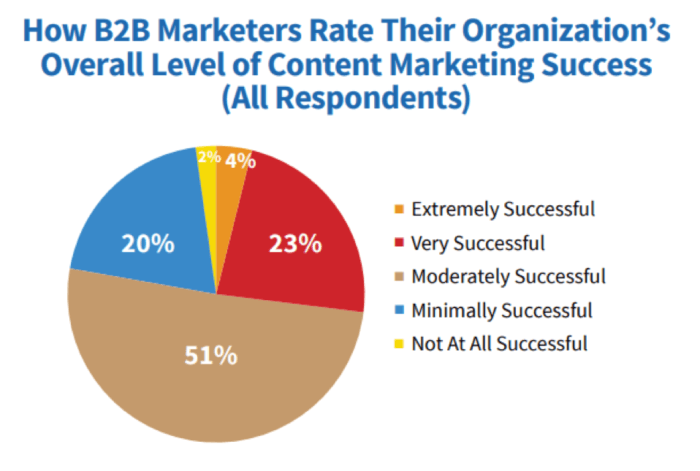
This means your competitors are certainly marketing their products or services with content and might be doing so successfully. How can you benefit from their success? Through competitor content analysis.
Why you should analyze competitors’ content
There are several benefits you can derive from the competitive content analysis. The main point is to grasp as much data from your competitors’ content strategy as you can. Just as if they were telling you the whole story with both ups and downs.
Identify top-performing and low-performing content
The most successful content pieces of your competitors are the first you need to keep an eye on and possibly replicate. These could be viral projects, collaborations, or in-depth articles. Learn what your target audience liked most and do it even better than your competition.
Another vital step is to find what content didn’t get much traction. This way, you can learn from competitors’ fails and mistakes. For instance, if they started conducting webinars but gave up a year after, this type of content probably didn’t drive much interest and wasn’t that profitable. Or they did it the wrong way.
Get fresh content ideas
Undergoing a writer’s block and can’t find another topic to cover? Skim through competitors’ content to get fresh ideas. Even if you have already filled up your content plan for the next year, it’s worth checking competitors content to find missing topics.
It’s not only about analyzing topics and headlines. Examine how competitors structure each content piece, how many headings and images they use, whether there are videos integrated into the text, etc.
Tweak your content strategy
Nothing is perfect and your content marketing strategy is not an exception. A competitive analysis allows getting insights into the content market in your niche, finding the low-hanging fruit and identifying competitors’ weak spots.
Unless you want to become another copy of the first page in search results, you should differentiate yourself and learn from competitors’ trial and error. The essential stage of the competitive analysis is to implement all the insights you get.
How to speed up competitive content analysis
First, take the three most prosperous competitors of yours. I hope you know them – you really should! It’s crucial to analyze businesses you compete with directly in organic search results not elsewhere.
Second, collect all their content in one place (URLs). Google Spreadsheets is perfect storage for this task. If there are several locations where different types of content reside, you need to check them all.
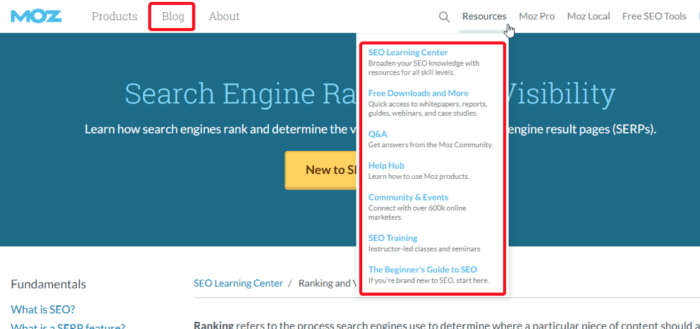
As you can see, Moz has a bunch of content hubs besides its blog. It could also be webinars, FAQ page, Help Center, and others.
The last but definitely not least, collect all essential parameters and analyze the heck out of them.
Automate content collection
Collect URLs of all competitor’s content pieces. You can easily do it with SEO crawlers like Netpeak Spider, Screaming Frog, Website Auditor.
Configure the tool to crawl only inside the directory where the content resides and start scanning. Carefully skim through the results to sort out irrelevant pages. For instance, those could be other language versions of the blog. Add the URLs to a spreadsheet.
Here’s an example spreadsheet with competitive blog content analysis template you can grab and adjust for your needs.
What content metrics to analyze
Now you need to collect all the essential data. The difference between regular content analysis and the competitive one is that you don’t have access to some data like bounce rate, click-through rate, or conversion rate of each content piece.
Though, there are still plenty of metrics you can get. What’s interesting is that the amount of data you can retrieve directly depends on your competitors’ willingness to share it.
Here’s a list of possible parameters you can check during competitive content analysis:
Performance metrics (number of shares, comments, backlinks, referring domains, traffic estimates). This is the most important set of parameters that will help you identify what content performs best.
How to get: scraping in an SEO crawler, tools providing data on backlinks and traffic (Ahrefs, Serpstat, SEMrush).
Meta tags (title, meta description, H1-H6 headings). Knowing them, you can analyze how competitors optimize their content for better click-through-rate from organic search, how many keywords they use in tags, and how they structure their content with headings.
How to get: most SEO crawlers show this data by default.
Content length (a number of words and reading time). Perfect content length is a controversial topic. Spy on your competitors to check what length works best in your niche.
How to get: an SEO crawler.
Additional data (anything useful you can see on a page; for instance, an author name, number of images/videos per post, category or tag the content relates to). Identify what categories get the most attention. Find influencers contributing content to your competitors.
How to get: scraping in an SEO crawler.
Setting an ordinary crawl and getting data from a backlink tool is a piece of cake, even for a beginner. Though, as you can see, it’s not enough if you want to get the full picture.
At this stage, web scraping comes in handy. I’ll show you how to scrape the most critical metrics from competitors’ content.
Web scraping for content analysis
Many digital marketers falsely believe that web scraping is something that requires coding knowledge. In fact, it’s not rocket science. Let’s see how you can scrape data from competitors’ websites.
Let’s assume we want to analyze articles on Ahrefs blog. Open a blog post page and examine what data could be useful for further analysis.
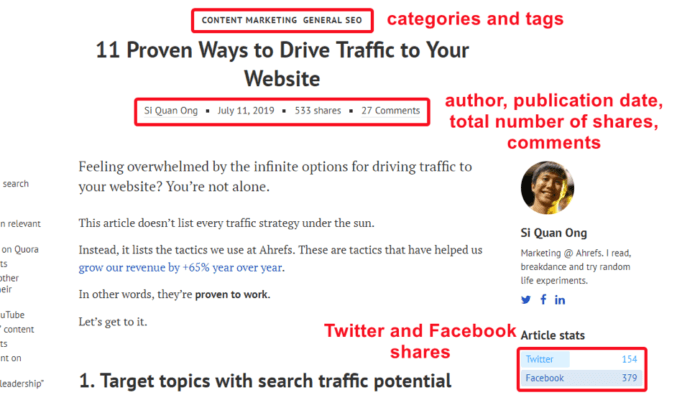
On the very first screen, we can see the following publicly available data:
- Category the post relates to
- Author
- Publication date
- Total number of shares
- A number of comments
- A number of Twitter and Facebook shares
There are two main scraping methods you can use: by XPath and CSS Selector (follow the links to learn their syntax). Both methods allow extracting data based on specific patterns or its location.
Mostly, you can use CSS Selectors to scrape any data.
To find scraping patterns of each parameter, open DevTools by right-clicking on the corresponding parameter and clicking ‘Inspect’.
Find unique identifiers of your parameter. In this case, we can see that both category names have a parent div → class=”post-category”.
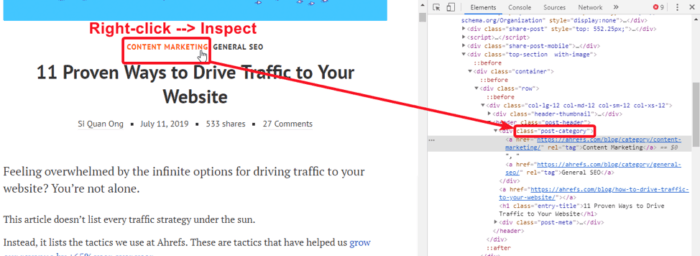
Here’s how CSS Selector and XPath scraping conditions will look like:
CSS Selector: [class=”post-category”]
XPath: //div[@class=’post-category’]/a
Same for other parameters.
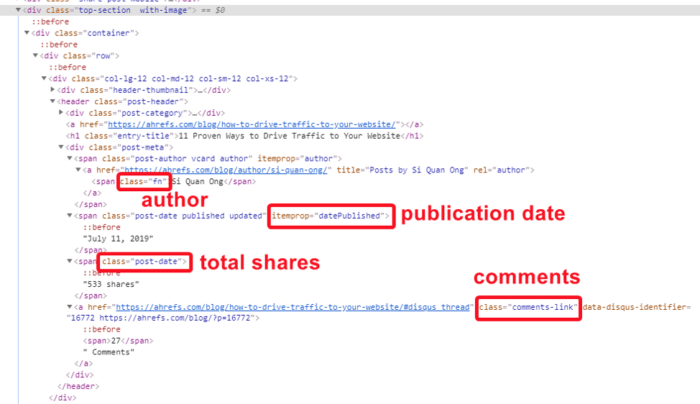
That’s what we’ve got:
Author → CSS Selector → [class=”fn”]
Publication date → CSS Selector → [itemprop=datePublished]
Total shares → CSS Selector → [class=”post-date”]
Comments → CSS Selector → [class=”comments-link”]
Oh, we nearly forgot about Twitter and Facebook shares.
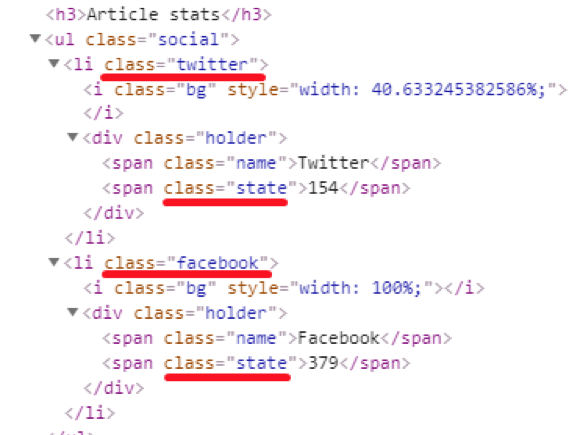
As you can see, both values we need are located under the same class → “state”. Using [class=”twitter”] and [class=”facebook”] will give us ‘Facebook/Twitter + number’ since they both have two child tags, and we need only one of them.
To be more precise, we can use several identifiers:
Twitter shares → CSS Selector → [class=”twitter”] [class=”state”]
Facebook shares → CSS Selector → [class=”facebook”] [class=”state”]
Add all scraping conditions to the SEO spider (let’s take Netpeak Spider as an example). Try crawling one URL to test if everything works smoothly.
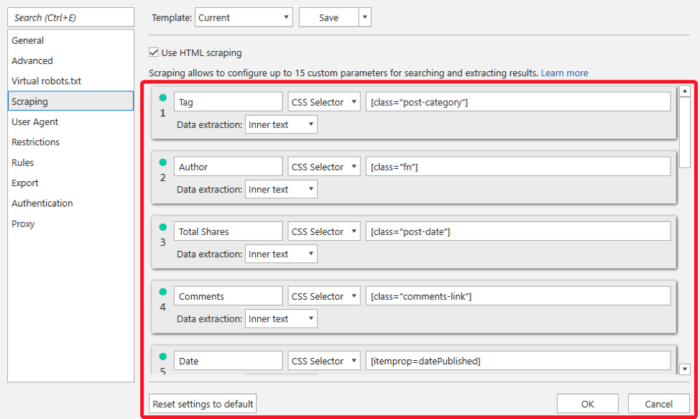
Make sure crawling of meta tags and the word count is enabled. Hit the ‘Start’ button and make yourself a cup of tea.
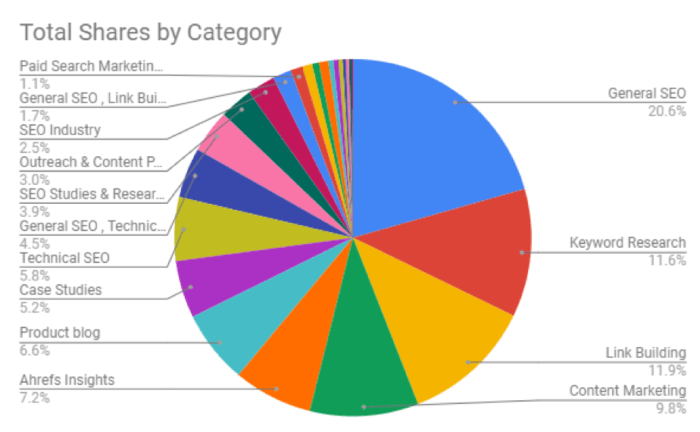
When crawling is done and dusted, copy the results and paste them to your spreadsheet. Use pivot tables and create custom graphs for better visual perception.
Final thoughts
Competitive analysis is the foundation of content marketing strategy. It’s not enough to take a shufti at competitors’ content. If you want to get a deep insight into the competition, you have to base your research on as much data as you can get.
Automating data collection, you save hours spent on monkey job. Thus, you have more time for an in-depth analysis.