

January 10, 2019
 |



NOTE: Please use these links to catch up on the previous posts in the series: Article 1 / Article 2 / Article 3 / Article 4 / Article 5
By: Denica Masby & Cindy Krum
In the past few months, we are seeing more and more evidence that Google’s Mobile-First Indexing is not just a change of the primary crawler, but a major shift in Google’s strategy for organizing information and processing queries. The relationship between languages and entities in Mobile-First Indexing, or as we call it at MobileMoxie, ‘Entity-First Indexing,’ can not be overstated.
Language can be more important for some topics or search queries than others. For example, language now plays a minimal role in Image Search results because Google is translating the title tags of all the relevant images, and presumably ranking the images based on those translations, and the other normal signals, rather than basing the rankings on the un-translated text; as discussed in Article 4 of this series, the intent of an Image search is visual, so the language of the textual content surrounding the image is inconsequential. This is the essence of the relationship between languages and entities in SEO. Removing language as a primary signal for understanding a query and ranking the results.
Our research indicates that Google is trying to build-out its understanding and proficiency in ranking non-English queries by fine-tuning its Entity Understanding of the web, and this is core to the change. This new strategy of categorizing and re-indexing information is based on a Knowledge Graph-centered index that uses information from mobile devices to help Google serve the best results for the individual user. With this research, we aim to provide a deep understanding of Google’s new method for determining the best individualized search results using engagement patterns, physical location and phone specifications, rather than simply relying on information from the browser.
While traditional organic (blue-link) rankings have been in flux recently, Mobile-First Indexing focuses much more on making it possible for Google to rank more rich content in multiple position-zero entries, above the traditional organic (blue-link) results. Google is trying harder to surface answers to the queries being submitted directly in the SERP, rather than just returning a list of websites, and this strategy fits well with Google’s major focus on the Assistant and voice-only/eyes-free search. Since Google hosts the Knowledge Graph and many of the other assets that are shown in position-zero, they can translate them as needed, based on their understanding of user-intent. This organization of search results is the simplest illustration of the relationship between entities and language in the future of SEO, especially when the settings that impact language are explored in detail.
This is the last article in MobileMoxie’s five-part Entity & Language Series. The first four articles discussed what Entity-First Indexing is, Google’s strategy for re-indexing content in Mobile-First Indexing, how Google’s language APIs work in search and what linguistic factors impact Google’s algorithmic Query Understanding. This article will combine the learnings from all of the previous articles, and add in information about when and how Google is changing search results based on various language signals sent from the phone, search settings and user’s Google accounts; it will outline which signals Google uses to detect and serve the correct language in searches from both Chrome and the Google App. It will then provide a detailed explanation of how translation in Knowledge Graph and other Google-hosted results may play out in other SEO scenarios, especially as Google gets better at indexing and surfacing content that is less reliant on URLs.
Jump To:
Historical Impact of Language on Search
Sometimes, it can be tricky for Google to determine what the right language of a query result actually is – especially when users search in languages that do not match their normal search patterns. Historically, Google used the searchers physical location, and the Google ccTLD where they started the search to determine the language of the results. This was especially important before Google launched their own browser, (Chrome) or allowed people to create individual Google accounts. Now that the adoption of Chrome and Google accounts is near ubiquitous, Google sometimes also seems to rely on a users Google account settings, browser settings and search settings to help determine the appropriate language for search results. Since the change to Mobile-First Indexing, Google is relying more and more on the physical (GPS) location of the searcher and the searcher’s language settings on their phone or in their Google account, to direct the search results that are returned. This is a distinct shift towards more personalization in search results that Google has long been striving for.
Previous to the launch of Mobile-First Indexing, Google used different local algorithms for different countries and sometimes even redirected users to the country-specific top level domain names (ccTLD) before a search could be submitted. The local algorithm was determined by the ccTLD, so if a user in the US began a search in google.co.in, then they would have seen search results for India. In countries where multiple languages were spoken, Google would try to recognize the language of the first search query, and then ask if the user wanted to continue searching in that language, or search in a different local language that it suggested.
This changed just before the launch of Mobile-First Indexing. Since October 2017, search results have been determined by the phone geo location. Google is still redirecting to the local ccTLD in some territories, but the localization of the results is determined by the location of the phone, not by the ccTLD extension. Now it appears that in many queries, Google is prioritizing the phone language settings over the physical location of the searcher, the Google ccTLD and even the Google account settings.
Recently Google clarified that localization plays a more significant role in search than personalization does. In a tweet, Google Search Liaison Danny Sullivan pointed out that they “do not personalize search results based on demographic profiles nor create such profiles for use in Google Search”. Danny also recommends comparing personal results and Incognito results to review SERP differences. According to Danny, the main reasons for results to differ are “location, language settings, platform & the dynamic nature of search”. Over all, localization, language and platform (OS and/or app) seems to be the most useful way for Google to make results more relevant, so this is what we set out to test.
Historically, when Google used keyword matching to conduct a search, the language of the results would almost always match the language of the query. Over time, we have seen keyword matching results skew to begin returning results in the users preferred language, even when it does not match the query. We believe that this is changing due to Google’s expanding ability to access user’s language preference from their mobile devices – especially on Android. Android and iOS signals vary but it seems that both send signals about the language preferences set on the phone. In the grid below, we have presented the different signals for both operating systems. It appears that Google does not count this as ‘personalization,’ but instead as ‘localization.’
Summary of the Language Signals We Tested: |
Android |
iOS |
| – Query Language | yes | yes |
| – Location Detecting | yes | yes |
| – Phone Language Settings | yes | yes |
| – Google Cloud Language Settings | yes | yes |
| – Search Settings | yes | yes |
| – iCloud Language Settings | no | yes |
Google Search in the Browser vs. The Google App
Before going any further, it’s also important to differentiate Google Chrome(![]()
![]()

Recently, Google search results in Chrome and other browsers are becoming more and more like the experience in the Google App. Google has already specified that Chrome 69 will essentially require users to be logged in at all times. For awhile now, the search bar that is included by default on the main screen of Android devices has led to results in the Google App, rather than the browser. With this in mind, we can speculate that for both iOS and Android, Google intends to rely heavily on the Phone Language Settings or the Google Cloud Account Language Settings and only use the Google Maps Geolocation API and the Native Language API as additional reference points for Entity Understanding in search, but not for determining the language of the results. To learn more about how these two API’s are already impacting search results, please view the third article in this series, Translation and Language APIs Impact on Search (3 of 5).
Language Signals Used by Google & Their Impact on Search
As described, there are a variety of signals that Google can use to determine the linguistic intent of a search. These include information and preferences that are saved in the cloud accounts hosted by Google and Apple, and the settings on the phone, which Google has access to whenever one of their apps (Chrome or the Google App) is added to the phone. Our testing indicates that Google can access the following language signals from all modern devices: Query Language, Location Detection, Phone Language Settings, Search Settings and Google Cloud Language Settings; but these have different impacts on results in the iOS and Android versions of Chrome and the Google App. When it comes to iOS, the iCloud Settings can bring an additional level of complexity, which will be discussed later in this article. The following sections will outline how Google detects language settings in both Android and iOS search scenarios, and how the settings impact the search results:
Android
To determine which language settings were the most important to Google in an Android environment, we designed a test where all of the possible language preference settings were different languages; this would help us find out what the strongest signals were. We tested results in both Google Chrome and the Google App. Since, we conducted our testing from the USA, we avoided using English, the default language of the US, in any of these settings. This would guarantee us that if we see English results, the signal comes from a location detection not from other settings.
We started our testing by switching a Pixel 3 phone settings to Spanish, and changing the Google Cloud Account settings associated with the phone to Bulgarian. We also changed the Search Settings in Google Chrome to Japanese. (NOTE: The ability to change the Language in ‘Search Settings’ is available only in Google Chrome – the option to change it is not present in the Google App.) Within Search Settings, users are given the option to change both the ‘Language in Google Products’ and the ‘Language of Search Results’, but the ‘Language in Results’ setting always matches the ‘Language in Google Products’ setting. When you add additional languages to the ‘Language in Search Results’ setting, Google still prioritizes the main (first) language on this list. To ensure the accuracy and quality of the test test, we needed to change the ‘Google Products Language’ to Japanese and remove the additional language (English) from both settings; this would guarantee that the only signals sent by the Search Language settings were Japanese. For more information on how to change the language settings on your Android phone click here.
Even though we changed the ‘Language in Google Products’ in Chrome, the language setting in the Google Account was not impacted – it remained set to Bulgarian, but began returning a note that said, “Some products are not using Bulgarian” with the option to ”CHANGE ALL” (Example images below are in English for clarity).


In the grid below you can see the language diversity in the testing. We conducted the test in USA, which sends a signal for the default language, English. We tested a Greek query (Φύλακες του γαλαξία, Guardians of the Galaxy), on a phone with Spanish settings, linked to Google Cloud account in Bulgarian and Chrome Search settings in Japanese.
| Android | |||||||||||||||||
| Phone Setting | iCloud Settings | Google Cloud Account | Search Settings | Location | Query Language | ||||||||||||
| Spanish | NA | Bulgarian | Japanese | USA/English | Greek | ||||||||||||
We did the same test, using the same settings three different ways: in the Google App, Google Chrome logged in and Google Chrome Incognito. The results are outlined in a grid and summarized below:
| Language Settings | Google App | Chrome Logged In | Chrome Incognito |
| Results & Relevant Language Setting | Spanish (Phone Settings) | Japanese (Search Settings) | USA, English (Default for ccTLD) |
| Notes | As illustrated below, the Google App returns search results in the Phone Language, which led us to believe that Google prioritizes the Phone Language as a top signal. This makes sense, because it is a language that the user selected themselves and likely understand fluently. | As you can see below, when logged into Chrome, the search results were returned in Japanese, the Search Language we used in the Chrome Search Settings. We also did the same test with Search Settings Language not specified, and in this case, the search results matches the Google Cloud Account Language Settings (Bulgarian). This shows that the Google Search Settings in Chrome can override the Google Cloud Account Language Settings. | This is the option where Google has the least information about the user, so language assumptions are hard for Google to make. As you can see illustrated below, when logged out, searching in Google Chrome Incognito mode, search results came back in English. This was either based on our physical location in the US or more likely because English is the default language of the ‘.com’ version of Google where the search was submitted. |
 |
 |
 |


NOTE: For Chrome Incognito mode, the SERP included this note: “Tip: Search for English results only. You can specify your search language in Preferences” which links to Search Settings in Google Incognito mode. Apparently, if it is not specifically set, the search language for an Incognito search seems to match the default language of the Google ccTLD, but they appear to be testing different options. In the past few weeks, we have sometimes seen Google Chrome Incognito searches returning results in the Phone Settings Language, the same as the Google App.
iOS
In iOS, iCloud language settings add another level of complexity so we needed to add an additional language to the test. The language diversity in the iOS testing was the same as the Android testing, however we specified German for the iCloud Settings. Again, we conducted the tests while physically located in the USA, using Google.com, so that would explain any English results. Again, we tested the same Greek query (Φύλακες του γαλαξία, Guardians of the Galaxy). Since Chrome is not the default browser on iOS devices, we also tested results in Safari. The language various languages and corresponding phone settings for this test are outlined below:
| iPhone | |||||||||||||||||
| Phone Setting | iCloud Settings | Google Cloud Account | Search Settings | Location | Query Language | ||||||||||||
| Spanish | German | Bulgarian | Japanese | USA/English | Greek | ||||||||||||
For more information on how to change the language settings on your iOS phone click here.
As you can see below, in iOS the language selected in the phone settings had priority over the iCloud Settings and all other settings unless a user had used the browser to alter their Search Settings in Google from the browser.
| Language Settings | Google App | Chrome Logged In | Chrome Incognito |
| Results & Relevant Language Setting | Spanish (Phone Settings) | Japanese (Search Settings) | Spanish (Phone Settings) |
| Notes | Similar to Android, the Google App used the phone language as the primary setting for determining the language of results. | When testing logged-in to the Google account from Chrome and Safari, both results were returned in Japanese, the Search Language we set with Google from the browser. If we did not specify the Search Settings Language, results matched the Phone Settings by default. | Both, Chrome and Safari returned results in Spanish, the phone language. |
 |
 |
 |

The biggest difference between Android and iOS is in logged-in Chrome. On an iPhone, if users do not specifically change the Google Search Language Setting (from the link at the bottom of the SERP), Chrome and Safari will match the Phone Language (Spanish). So in iOS the phone settings are a stronger signal than Google Cloud Account, but the phone settings can be overwritten by the Search Language that is set in Google from the browser (Japanese).
When it comes to iOS, we needed to consider an additional testing in Safari, logged in and logged out in Incognito mode. The results matched the Chrome results, as you can see below:
| Language Settings | Safari Logged In | Safari Incognito |
| Language of the Results | Japanese (Search Settings) | Spanish (Phone Settings) |
| Notes | When testing logged into the Google account from Safari, both results were returned in Japanese, the Search Language we set with Google from the browser – Just like in Chrome. Similarly, when we did not specify the Search Settings Language, results matched the Phone Settings by default. | Both, Chrome and Safari returned results in Spanish, the phone language. |
| Result |  |
 |
Summary of Results:
After the testing, we see obvious patterns in the language of the results strategy, which is good, because after testing many times over many months, we also noticed that the impact of some of the settings was in flux; Luckily, there was a pattern there too! Whichever settings changed in Android was followed, a couple weeks or up to a month later, by the same changes in iOS. The grid below represents the final results for all tests. Overall, in Google App, Google returns results matching the language of the phone, since it is a language the user speaks and chooses when he/she set the phone. In Chrome, Google returns results in the Search Language but when the Search Language is not set, Google uses different signals to determine the best language for the results, depending on if the user is on an Android or iOS phone and if they are searching in Incognito/Logged out or logged-in mode.
| Android | iOS | |
| In Chrome | Search Settings Language Matching Google Cloud Language if Search Settings are not specified |
Search Settings Language Matching Phone Language if Search Settings are not specified |
| In Chrome Incognito | Search Settings Language Matching Location or ccTLD Default Language if not specified |
Search Settings Language Matching Phone Language if Search Settings are not specified |
| In Google App | Phone Settings Language | Phone Settings Language |
| In Google App Incognito | N/A | N/A |
| In Safari | N/A | Search Settings Language Matching Phone Language if Search Settings are not specified |
| In Safari Incognito | N/A | Search Settings Language Matching Phone Language if Search Settings are not specified |
It seems that the Google Search Settings are the strongest signal on both iOS and Android devices – likely because this has to be actively set by the searcher. If the searcher is using the Google App or if the language in the browser-based Google Search Settings is left to default, with no language specified, (which we imagine is quite common,) Google uses the Phone Language Settings to determine the right language for iOS results. In the same scenario for Android, the Google Cloud Language setting may be used by the browser, the Phone Language Settings will be used by the Google App or the default language of the Google ccTLD or the physical GPS location will be used when Incognito. Google never uses the iCloud Language Setting, or the Query Language to determine the language of the query results, and they rarely use the Google Cloud Account settings.
Here is the kicker: All of that research is just representative of the Knowledge Graph – not the rest of the results. All the traditional organic results (blue links) below the Knowledge Graph were in Greek, the language of the query. Google was determining the language of the organic results differently, and in a much less sophisticated way, based on simple keyword matching! As you can imagine, we take this as a strong signal that position-zero style results, especially Knowledge Graph results are critical for Mobile-First Indexing. Google is putting much more effort into getting the language right in these results, compared to traditional organic rankings.
What we found is that position-zero results are translated to optimize for personalized language settings, but regular organic blue-link results are not. You can see this again in a comparison of the book query ‘War and Peace’ below. Both queries are from a phone that is physically located in Bulgaria, with Bulgarian phone settings. Only the Knowledge Graph and Book Carousel are translated to Bulgarian to match the Phone Language Settings. The rest of the results are in English. This is particularly interesting because Bulgarian is not one of the languages of priority, included in the Cloud Natural Language API:


With similar thoughts in mind, we compared the search results of the same query in English between a phone in Bulgaria, searching from the Bulgarian Google ccTLD, Google.bg, with Bulgarian Phone Language Settings and and a phone in the USA, searching from Google.com, with Bulgarian phone language settings. In this one, you can see below that all of the results are in English, with only minor differences between the two ccTLD – likely caused by differences in trademarked brands like Pillsbury being popular and available in the USA but not Bulgaria. But you can see that Phone Language Settings appear to have little or no impact on search results that don’t include Knowledge Graph, regardless of what version of the ccTLD is used to submit the search:


Entity Understanding and Translation Process
Overall, entities provide Google a better and deeper understanding of topics because they give Google the ability to easily develop connection and relationships between different topics (entities). Deeper understanding of an Entity and its relationships, in turn, gives Google the opportunity to potentially serve information about the Entity in any language (with live translation from the Google language APIs if necessary), since now the language has only a supportive role for the query – like a modifier. Whatever Entity Understanding and Entity Relationships Google learns in one language can automatically be translated to other languages, especially in Google-hosted, position-zero results like the Knowledge Graph.
Google has been working actively on their Cloud Datastore of entities. Each entity has a numerical Entity ID, which is associated with the Knowledge Graph; (remember from the movie Contact, math is the universal language!) The Knowledge Graph Search API lets you find entities in the Google Knowledge Graph by search, or simply by the Entity ID. The API uses standard schema.org types and is compliant with the JSON-LD specification. It also lets you find relationships of one entity to another, that are understood in the Knowledge Graph. Some of the types of entities found in the Knowledge Graph include: Book, BookSeries, EducationalOrganization, Event, GovernmentOrganization, LocalBusiness, Movie, MovieSeries, MusicAlbum, MusicGroup, MusicRecording, Organization, Periodical, Person, Place, SportsTeam, TVEpisode, TVSeries, VideoGame, VideoGameSeries and even WebSites.
We believe that now, differentiating ‘the content that Google hosts’ from ‘the content it does not’ is becoming critical for SEO; It is an indication of what content Google can translate and serve in a SERP in different languages.As shown in the example below, each Entity is associated with an Entity ID, so that it can be located and understood in many languages; Google will return results associated with this Knowledge Graph and may translate the language of the Knowledge Graph results according to the searcher needs.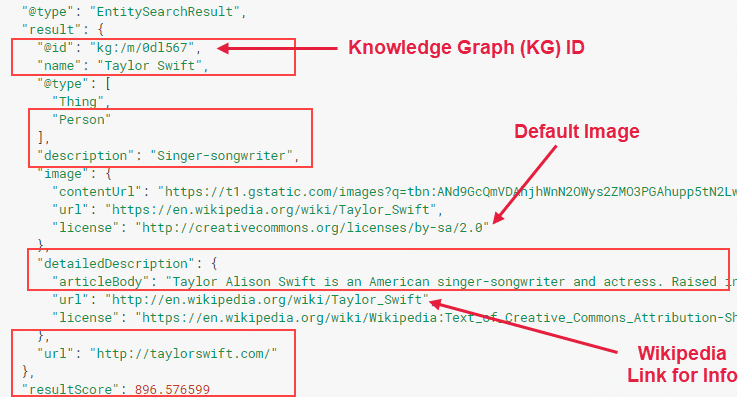

Image: Google (modified by MobileMoxie)
With all that, it is critical to make it as easy as possible for Google to recognize and access business entities and their relationships. This might make it possible for Google to lift and translate extra content into its position-zero results, which could be very strategic, especially when it comes to international content. Currently, the Google Translation API uses Neural Machine Translation (NMT) to understand queries, but relies on English as the ‘hub-language’ for the translation of languages that are not included in the Cloud Natural Language API (an indication that they are already understood with native proficiency), as diagrammed in Article 4 of this series.
The top of the SERP is no longer dominated by websites, so understanding Google’s new SERP structure and position zero results is critical for SEO. With Google’s new Entity based understanding, the language of the entity and content does not matter as much anymore – at least in some languages, and for some queries. Content can be clustered in the index based on the entity understanding, without being omitted because it is in the wrong language. Now, the availability of good Knowledge Graph information is based on the presence or absence of the information in the Knowledge Graph at all, in any language, and that information can be translated to suit the user needs based on the language signals they are sending to Google. Of course, HREFlang tagging can make this process even easier because it allows Google to index information to the Knowledge Graph based on the English or default version of the content and use the tagging and language APIs to organize the non-English content without relying so heavily on crawling it and understanding each translation independently.![]()

This ability to translate on the fly could be expanded to other kinds of informational queries soon. Recently, Google has begun to rank pieces of web page content (on-page content fragments) independently of each other, and linking to them with inserted handles or bookmarks, especially when there are multiple possible answers to a query located on one page. We call these Fraggles – a combination of the word ‘fragment’ and ‘handle’. As shown below, jump-links in search results, scroll the user directly to the relevant content, even though there is no handle or bookmark included for it in the code. Clicking on the jump-link not only opens the page but scrolls to the part of the page where that specific content is located on the page.
NOTE: It appears that heading tags, Schema and linked content ID’s may be helping drive this type of result. By marking content with heading tags (shown below), we can help Google to locate the unit of content they need and serve it to a user as a Fraggle. We think Google may also be using CSS classes and x-Path locations to create these – especially when those things are also associated with Schema.


This is a clear illustration Google is changing the way they crawl and index the content on the pages and we speculate that in the long-term, it may be for the benefit of providing quick, voice-answers to queries; and further, Google may begin to translate results in Fraggles, for voice and visual search, showing the results in position-zero like Knowledge Graph. This is also important as more and more PWAs and especially SPAs can begin to rank Fraggle content, even without the content being on different URLs.
Query Ambiguity and Query Language Impact in Search Results
It is important to understand that the research above was just focused on Knowledge Graph (though we suspect it may soon impact other position-zero results). The language of a query seems to be easier for Google to determine once the idea/concept has been indexed in the Knowledge Graph. Knowledge Graph association may make the intent is easy to detect – especially for movies, personalities, images, etc. We call this ‘direct intent’ because Google has a direct understanding of the query based on a Knowledge Graph entry. But during our testing we also noticed that queries without ‘direct intent,’ when the intent of a search query may be ambiguous or broad, Google returned results differently than it would have if a Knowledge Graph entry was present. With this in mind, we wanted to take our research just a tiny a step further, to find out what elements and settings impact the results for more ambiguous queries.
The research started with a search for ‘Red shoes’, which easily could be a search for a product, image or an old movie. In queries like this, with ‘broad intent,’ the Query Language complicates the search; Google appeared to prioritize different Google Assets, such as Images, Knowledge Graphs and Shopping results, based on the query language more than the other language settings. The example below shows a test in the Google App for a search query ‘Red Shoes’ in Bulgarian, Greek and Spanish. The search was conducted from the USA, on a phone with English settings. As we expected, Google returned the Google Assets in English, the phone language, but what was surprising was that Google returned different Google Assets, depending on the query language, potentially indicating that the Knowledge Graph may associate different assets with different degrees of intent, depending on the Query language. Again, as with the organic results below the Knowledge Graph in our previous tests, the blue links that Google returned below the Google Assets were generally in the language of the query.
| Phone with English Settings in the USA | Greek Query ‘κόκκινα παπούτσια’/’Red Shoes’ | Phone with English Settings in the USA | Bulgarian Query ‘червени обувки’/’Red Shoes’ | Phone with English Settings in USA | Spanish Query ‘zapatos rojos’/’Red Shoes’ |
 |
 |



To verify our understanding of the process, we repeated a test from a previous article in the series – testing search results in the Google App for various translations of the famous Mexican movie ‘Y Tu Mamá También’. Our goal was to assess the impact of a potential ‘broad intent’ query in search results. For this one, the intent could be considered ‘direct’ in Spanish, because there is a Mexican movie with this exact title. In other languages, the intent could be considered more ‘broad’: Spanish (‘Y Tu Mamá También’ [original language]), English (‘And Your Mother Too’), Greek (‘Θέλω και τη μαμά σου’), and Bulgarian ‘И Твойта Майка Също’). Thе query intent is most broad in Bulgarian since is also the title of a well-known Bulgarian hip-hop song, that can be found in YouTube. We anticipated that the song title, without translation would out rank the movie, with a translation, but that both would rank. (Since Bulgarian is a language that is not part of the Natural Language API, inclusion of a disambiguation prompt was not expected.)
As shown below, all of the search results, except the Bulgarian test, are returned in the Phone Language (English) with Knowledge Graph results for the Mexican movie. In the Bulgarian test, the Knowledge Graph result is one about the Bulgarian hip-hop song not the Spanish Movie. While it was a little unexpected, it was not too surprising – the song is very popular, so it makes sense why Google would have indexed the song result for user relevance (most likely, after noticing that more users tend to click on the YouTube video when searching in Bulgarian). This led us to believe that Google also uses the Query Language, not only the location, to determine the results they serve to users. And this is not always a personalization but localization and intent driven by language choice. It seems that even though they may understand queries similarly in a variety of languages, they are probably using machine learning and click-data segmented by query language, to determine what ranks, regardless of the Phone Language or the location of the searcher.

Conclusion:
After our testing, we believe that there are are a variety of elements that can impact the language of a search result, and that these things change between regular organic results and Knowledge Graph or other position-zero Google Assets. This is great for ‘direct intent’ queries, for which Google can easily make an association with something in the Knowledge Graph, but adds complexity for ‘broad intent’ queries for which the intent is less clear. In these cases, Google may vary the Google Assets that are shown in position-zero when the same query is submitted in different languages, but all other settings are held constant.
With all this, we can speculate that Entity Understanding in the Mobile-First Index is meant to help Google learn more, faster, to cross populate information in different languages, but also to help Google get better at understanding search intent in all languages. This is why they would unify the various languages with universal Entity ID’s, but still alter results based on click-data that is specific to a Query Language. This system also makes it easier to ensure that the position-zero results, which could potentially be read as voice results, are in the correct language for the user. Google is constantly working to improve user experience by delivering accurate, relevant information, as quickly as possible, but the growth of voice search makes it even more vital that it the results are also in the correct language. Being able to do this accurately for users where and when they needed is the goal of the Mobile First Index. This goal makes Entity Understanding critical for Google’s fine-tuning of Mobile First Indexing because Entity Understanding is what gives Google the ability to efficiently and accurately process loads of information from around the world, in a sustainable way.