

June 22, 2018
 |



NOTE: Please use these links to catch up on the previous posts in the series: Article 1 / Article 2 / Article 3 / Article 4 / Article 5
By: Denica Masby & Cindy Krum
Google’s Mobile-First Index, or as we call it at MobileMoxie – the Entity-First Index, is changing the way Google organizes information, especially in terms of language. In the past, Google used language as a primary defining element, to determine the correct search results for a query, potentially even to determine which part of the index or which algorithm they should use to process the query. Now, with Entity-First Indexing, we believe that Entity Understanding and search context have become more important for Google’s ranking and evaluation of top results, and with that, the language of the query has become more of a secondary factor, like a strong modifier. With the launch of Mobile-First Indexing, we believe that Google is switching from being organized in the previous methodology (likely based on the Link Graph) to being organized based on Entity Understanding derived from their Knowledge Graph, which is to some degree, language-agnostic. We are already seeing signs of this in search results now.
Google’s increased focus on Entity Understanding and decreased focus on linguistic keyword matching seems to play a huge role on determining the search results that they serve. Google’s recent change away from relying on country-specific ccTLD’s for passing language and country information, and the apparent internationalization of many of their other properties also feeds this theory. The timing of these changes made us think that their handling of language and their Entity Understanding in searches might be tightly related to the shift to Mobile-First Indexing. We also couldn’t help but notice the high level of focus on HREFLang discussion in John Mueller’s Spring AMA on Reddit, when one would expect much more of a focus on more mobile-focused topics that might be related to Mobile-First Indexing, such as PWAs, JavaScript, Deep Linking, App Indexing, Google Actions or Instant Apps. Seeing evidence of this increased focus on language, casually in our own search results motivated us to seek a deeper awareness of how Entity Understanding has begun to impact international search and SEO.
This is the third article in a five-part series about the topic of Entity Understanding and language in search. The first two articles in this series focused on the concept of Entity-First Indexing, how it manages to be language agnostic, and the tools we believe Google used to accomplish the transition from indexing based on the Link Graph to indexing based on the Knowledge Graph. This article and the next one focus on practical research that MobileMoxie completed to illustrate these points; testing international searches to show differences related to Google’s language detection and recognition in Search.
The final article in this series will provide further research to show new ways that Google is adapting search results for each user individually, based on the language settings on the phone they are searching from and the origin of the search (EX: if the search began in the Google App (![]()

Jump To:
Query Matching & Query Understanding
Originally, Google’s search algorithms and technology focused on English, because they were written by people who spoke predominantly English. Now Google’s ability to understand and respond accurately in many languages is critical to their continued success around the world. The ‘search’ part of Google’s algorithm initially focused on keyword matching, just like the other search engines at the time. They crawled and indexed the text of the web, and surfaced sites that included a match of the keyword that was submitted in the query. They sorted the matching web pages based on the frequency of the matching keyword occurrence on the page, and other signals, including inbound links and anchor text – but eventually giving special weight to keyword matching anchor text.
The important thing to know here is that none of this actually represented anything more than ‘query matching’ without any real ‘understanding.’ The difference in these two concepts really comes into play when the basic ‘sentiment’ of the search and the relationship between multiple words in the query is reflected in the results. At first, when early search engines were doing basic ‘query matching,’ they relied heavily on something called ‘boolean’ search modifiers or attributes to explicitly express the sentiment and the relationship between the words in the query. They included ‘AND,’ ‘OR,’ and ‘NOT;’ and were added before the keyword that they described, to allow searchers to string together multiple concepts; so a typical boolean query might look like this: “hotel OR motel AND denver.”
From a very early point with Google, the ‘AND’ was implied and did not need to be written. When options with both keywords connected by the ‘AND’ were not in the index, Google defaulted to the ‘OR’ attribute. ‘NOT’ wasn’t supported, but the results were still overall much better. This evolution by Google might represent the very most primitive level of ‘understanding’ in a query, but nothing like what we are used to today.
At the time, many search engines also relied on keyword popularity, as a ranking factor, so websites with popular keywords naturally ranked better for all queries, even if the topics of the keywords were minimally related. When SEO’s began spamming the web by including the most popular keywords over and over again on their pages, Google developed a capacity to understand synonyms, which broadened the primitive ‘understanding’ a bit more. This ‘synonym matching’ minimized the value of exact-match keyword spamming, and made it more valuable to include a variety of different keywords and their synonyms. When this system also started to be gamed, Google began adding and relying more heavily on other, external quality signals to help determine which pages were the best match for the query. Eventually, over time, Google was able to start using these external signals to further inform their understanding of the relationships – not only between the keywords in the query, but also the relationships between the website and the other similar websites on the web.
It was not until about 2005 when Google began building out the foundations of their Translation API, and they began to understand words in different languages as approximate synonyms. Now Google’s linguistic and translation ability and understanding in search are quite advanced.
How Voice Search Changes Query Understanding & Helps Get us to Entity Understanding
What many SEO’s seem to be missing is way that voice search changes these relationships, and how keywords work differently now, not only since the Hummingbird update, which focused on semantic and voice-driven queries, but also in the launch of Mobile-First Indexing. Over time, Hummingbird brought with it a lot of changes, especially related to local searches, and Google Map Pack rankings more accurate. Now, when SEO’s see their voice query directly translated to text and submitted to Google as a simple text query, they think nothing has changed, but we believe this assumption is incorrect. While the user-interface has remained constant, the back-end understanding of the query and the keyword relationships has changed.
Voice-queries tend to be longer than written queries, and they tend to include more inconsequential words. This makes it harder for Google to determine the most important part of a query, and return the related results without getting distracted by the extra keywords. This is where a more comprehensive Keyword Understanding becomes critical and Google is forced to rely more heavily on phrase-based matching and machine learning for keywords. The main technology that makes that easier is phrase based indexing, as described by Bill Slawski, as well as ontological based Query Understanding, which he describes perfectly here and here.
The other thing that makes surfacing the right content in long, complex voice searches easier and more likely for Google to get right is Entity Understanding. Entity Understanding is different from Keyword Understanding because it allows Google to identify specific ideas or concepts that might be especially important in a long, complex query. As outlined in the two previous articles in this series, entities are ideas or concepts that are universal, and thus, are language agnostic. Luckily for Google, in a voice query, they often represent the core thrust of the query. Entity-based search results allow Google to provide a somewhat accurate result, that can be further parsed or disambiguated, even when the nuance of the query is not entirely clear.
EX: If you ask Google, “Who was the drummer for The Cranberries in 1999?” it can visually surface the Entity result for The Cranberries (Knowledge Graph), which includes pictures and information about the band members, their instruments and hopefully the years they were in the band. In the same search, when it is submitted as a voice-only query, Google can respond conversationally, to get you to the information that you are trying to find by saying “Ok, I understand that you want to know about the band The Cranberries – is that right? Did you want to know something about the drummer?”
The important thing here, is the change in the background of Google’s functionality, focusing on Entity Understanding first, whenever possible, because it allows for ongoing verification and disambiguation of the query, easily in both a visual and voice-only context. If Google had misunderstood the query, and responded with “Ok, you want to know about cranberries, (the food) – is that right?” that would surface a different entity (Knowledge Graph result) entirely, the searcher would stop Google before too much computational power had been used to match all the keywords in the query, and before Google delved deeper to find an answer that might not exist because they were looking at the wrong entity; (since foods do not have drummers, they may have ended up looking for ‘a drum of cranberries’).
This kind of back-end processing makes the responses quicker and easier for Google to surface, often without feeling like there was a loss of nuance or accuracy, and we believe that this is a crucial part of the changes that came with Mobile-First Indexing.
Mobile-First Indexing also changed how Google approaches international markets, language detection and country relevant searches. Based on our previous understanding of how Google used and understood languages, we anticipated the process diagrammed below, so the testing that we will describe in this article series followed a similar path:
| Google Linguistic Intent Determination Process | Detect Query Language | Determine Query Understanding (when possible) | Determine Entity Understanding (when possible) | ||||
| Corresponding MobileMoxie Testing | • Alphabet Testing • ‘From’ Testing in Google Translate • Phone Location Testing (Described in the next article in the series) |
• Word-Order Testing • Idiom & Idiom Variation Testing |
• International Movie & Song Identification Testing |

Google Translation API vs. Google Cloud Natural Language API
Entity Understanding is important for voice search and Mobile-First/Entity-First Indexing, but potentially hard to replicate in different languages. Historically, to achieve proficiency in non-English based searches, Google focused heavily on developing language and translation APIs. More recently, they have focused on using machine learning to fine-tune natural language, conversation and contextual language understanding in top languages around the world for eventual use in many of their new products and technologies. To this end, Google has developed a variety of APIs and other utilities to help them work natively in the most prevalent languages, and translate accurately and comprehensively when they can’t do that. These various technologies have different strengths and weaknesses that can be leveraged together or separately, as needed to make the most of each potential translation scenario. To understand the changes in how language now factors into search and SEO, you must first have a general awareness of the two main APIs that Google uses to process language: The Google Translation API and The Google Cloud Natural Language API:
Google Translate API
The Google Translate API has been around for a long time and is the most widespread and straightforward of the language APIs, so it is the one that most people are familiar with. It powers Google Translate and provides translation between many languages. In the early days, it focused on dictionary-style keyword matching and translation. Now it is much more sophisticated, and uses both state-of-the-art Neural Machine Translation and Phrase-Based Machine Translation. These two technologies allow words to be translated together in groups, or as phases, to provide more cohesive meaning. (Google understands keyword searches as phrases, so it makes sense that they would also want to translate words together as a phrase too.) This translation model was introduced into Google’s Translation API a couple years ago and many competitive translation APIs do not have anything similar.
Before The Google Translate API can begin a query or a translation, it has to detect the language of the query, or the ‘from’ language for the translation. In the past Google was only able to recognize the language of a query when it was written in the official alphabet of the language, or based on the physical location of the searcher, but now The Google Translate API can identify languages most of the time without this, even if they are not submitted from a place where that language is spoken or in the official alphabet of the language. This can be complicated because in some languages, one word that is spoken exactly the same way can be written in many different ways.
Once the query or the ‘from’ language in a translation has been detected, The Google’s Translation API then attempts to process a translation request using the Neural Machine Translation (NMT) model because this is their most robust translation technology. (You can find a list of all the languages supported by the NMT Model here.) According to Google, the NMT is available for all languages ‘to English,’ with the exception of Belarusian, Kyrgyz, Latin, Myanmar, and Sundanese. Since it uses machine learning, the phrase matching in each language will continue to improve over time, the more the Translate API is used.
If the NMT model does not support translation in the requested language pair, the Translate API falls back to Google’s Phrase-Based Machine Translation (PBMT) model, which can translate phrases proficiently, but tends to be less accurate than the NMT model, presumably because it is less driven by Machine Learning. This model works more like keyword and synonym matching models, but focuses only on multi-word groupings. (You can find a list of all the languages supported by the PBMT Model here.)
Google Cloud Natural Language API
Google uses the Translate API to detect language and find keyword matched, but Google uses The Natural Language API (officially called Google Cloud Natural Language API) to detect meaning. This newer API relies heavily on Machine Learning and AI, but is NOT meant for translation per-se; Instead, when a query is submitted in one of the 10 languages that it supports, it simply determines the meaning of text natively, using context and linguistic structure, without using translation.
This API was discussed in the previous article in this series, from the perspective of an SEO tool, because it detects and infers the contextual meaning of words and entities in a sentence or a paragraph. The API can do this because it has a deep understanding of grammar and linguistic structure in the languages that it supports. It does the same thing for individual queries, using its linguistic understanding, sentiment analysis and Entity Understanding along with engagement data from previous searches to achieve understanding natively, in the original language of the query. It is this API that allows Google to detect ‘search intent’ from queries, including detecting when keyword order changes the intent of the query, and thus, should change the search results for that particular query.
Knowing the basic functioning of these two API’s should help you understand how we approached our researched. Based on what we found, an estimated summary of Google’s capacity for language translation and keyword understanding is outlined below. As you can see, Google’s translation capabilities include basic ‘word-by-word’ translation, ‘phase-based’ translation and ‘advanced conversational language understanding’ which incorporates the broader context of the words to achieve clearer meaning. Each of these levels of translation and understanding relies on one or more of the Google’s language APIs, and falls within a few various options:
Google API |
Google Translation API |
Cloud Natural Language API |
||
| Function |
Individual Keyword |
Keyword Phrase Matching |
Entity Understanding |
Language/Grammar Understanding |
| Levels Language Understanding | Basic
Word-by-Word |
Intermediate
Phrase Based |
Advanced
Natural, Conversational Language |
Advanced
Natural, Conversational Language |
| Google Utilities Leveraging the API |
Google Search, Google Translate, Google Play |
Google Search, Google Translate |
Google Search, Google Home & Google Assistant, Google Actions |
Google Search, Google Home & Google Assistant, Google Actions |
| Languages | Language Detection & Dictionary Translation
Only for Belarusian, Kyrgyz, Latin, Myanmar, Sundanese. No Phrase-Based Machine Translation (PBMT), Neural Machine Translation (NMT) |
Top 26 languages in the world.
(Specifically does not include: Belarusian, Kyrgyz, Latin, Myanmar, Sundanese) |
Top 10 languages in the world.
Chinese – Simplified and Traditional, English, French, German, Italian, Japanese, Korean, Portuguese, Spanish |
Top 10 languages in the world.
Chinese – Simplified and Traditional, English, French, German, Italian, Japanese, Korean, Portuguese, Spanish |
| Supporting Technology /Data |
Language Detection, Dictionary Translation |
Language Detection, Phrase-Based Machine Translation (PBMT), Neural Machine Translation (NMT) |
Entities Database |
Engagement Data*, Sentiment Analysis, Sentence Structure, Context Analysis |
*Data provided by users feedback
Alphabet Selection & Its Impact on Language Detection
The first part of understanding the meaning of a query is detecting what language it is in, so we wanted to find out when the Translation APIs involvement in this part of a search starts and ends. Historically, since Google used keyword matching to surface web content that corresponded with the keyword in the query, the spelling and how the word was written impacted what results would be included; Language detection was easier and Google could use physical location and the language-specific alphabets to determine the language of a query.
At the time, Google also used IP detection and redirection to guess what country the searcher was in, and get them to the corresponding, country-specific version of Google where they could submit their query; then, Google actually had language-specific algorithms that were triggered by the Google ccTLD where the query originated. At this time, it was common for international searchers to have a computer keyboard that featured letters in the official written language, so it was reasonable to assume that they would be searching in the official alphabet of the language. Initially, this combination of signals was reasonably accurate, and the alphabet that a searcher used when submitting a query helped validate the classification and refine the results.
Conversely, when phones first got on the internet, and began searching, they had physical, rather than digital keyboards, and native-alphabet keyboards were not always available in every language. Many people adjusted to typing in their language with the Latin alphabet. Optimizing for local searches in Latin alphabet was a good SEO strategy at that time, because it expanded the market for your products – especially for mobile searches. On the other hand, some international businesses strived to localize mobile content with the ‘correct’ native alphabet, and not use the Latin character options for writing, but from an SEO perspective, relying only on native writing, and not including both native and Latin was especially limiting for mobile search.
With all this in mind, we wanted to find out if Google uses the choice of alphabet as part of the search context and if changing the keyboard or characters used to submit a search query would change the search results.
In the grid below we have included simple alphabet variation in two languages – Spanish and Hindi to illustrate this concept. Spanish relies predominantly on the Latin alphabet for written communication so it does not have much variation with specialized alphabets – Occasionally accent marks are included in proper written communication, but no new characters are added. Hindi on the other hand, uses a completely different alphabet called Devanagari, which is necessary for proper written communication. Most speakers have adapted to writing Hindi words with Latin characters in mobile, using phonetic spelling of the words. The two alphabets, Latin and Devanagari, are rarely used together.
| Language Test | Native Alphabet | English Word | Local Translation Variations | Content Type |
|---|---|---|---|---|
| Spanish | Latin with accent marks | And Your Mother Too | Y Tu Mamá También Y Tu Mama Tambien |
TV and Movie |
| Hindi | Devanagari | Will You Marry Me? | मुझसे शादी करोगी Mujhse Shaadi Karogi |
Music/TV and Movie |
From a search engine and language detection perspective, these two scenarios are in stark contrast to each other; When searchers write in Hindi, using the Devanagari alphabet, they rarely mix in Latin characters, but when Spanish speakers search, they casually include or omit proper accenting above Latin characters.
In the example searches below, in both Spanish and Hindi, you can see this concept at play. Google Instant, Google’s utility for anticipating and suggesting queries as a user types, based on query volume and machine learning, still manages to provide autocomplete suggestions for keywords in all different character variations, interchangeably, including the native alphabet and Latin options, despite the original query being written with only Latin characters. In general, it seems like Google orders the original query, including the alphabet choice, at the top of the Instant suggestions. This is especially true when a related Entity is available, but they do not do it to the exclusion of non-Latin query suggestions.
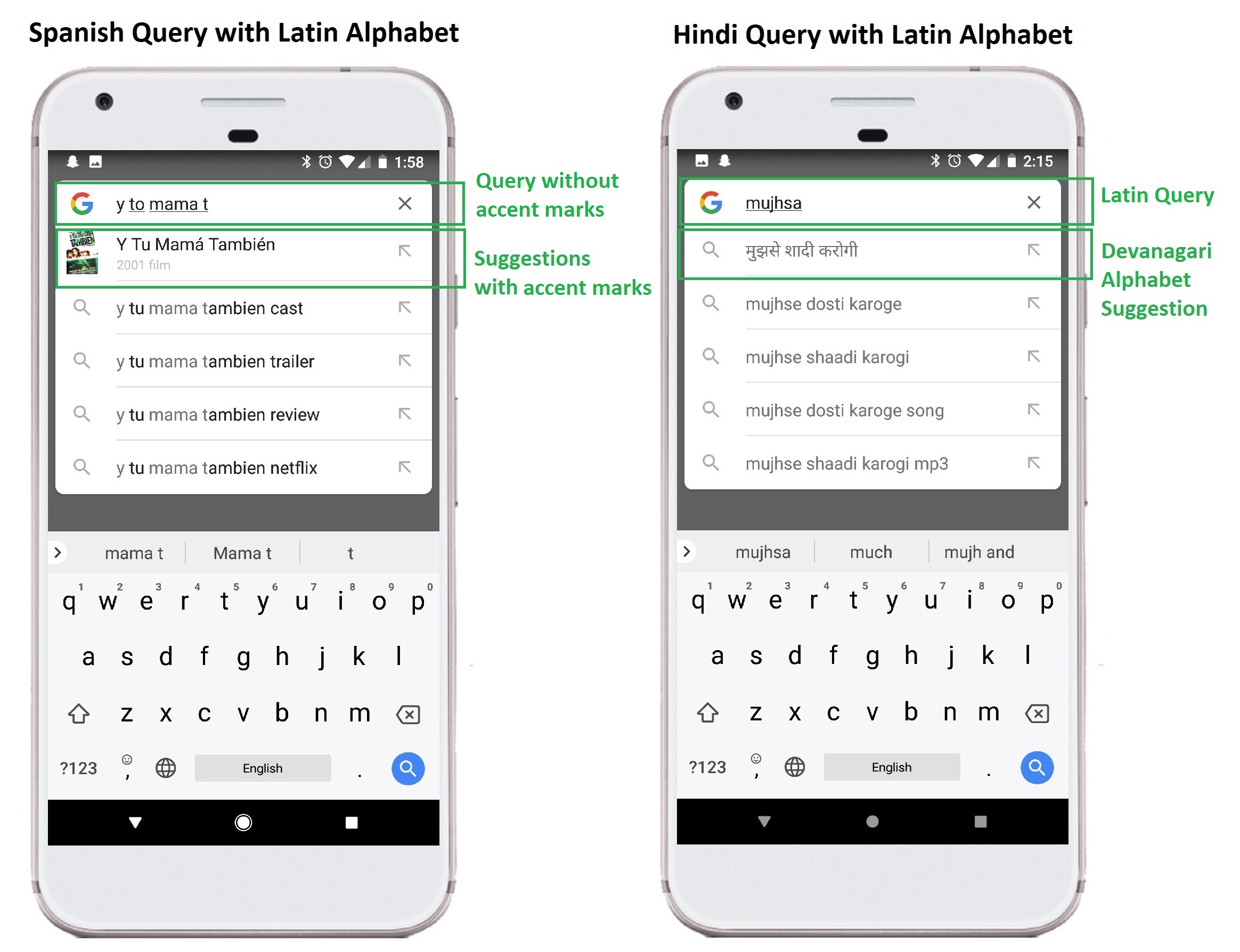

The language of a query is easy to detect when it is written in an alphabet that is specific to the language, like Devanagari, but harder when the query is written in Latin and other shared alphabets. Accent marks in the Spanish query may help Google determine when a query is in Spanish, but not much because they are only on some letters. The meaning of the word is not substantially changed if they are missing, so searchers include or omit them casually, making them less helpful in language detection.
NOTE: In this test, it is relevant to note that movies and songs are potentially even more variable than many informational queries that are not simply about local businesses. The words used in the media titles often break norms of language and contextual understanding, and thus, would be hard to associate with a proper meaning without some level of Entity Understanding. In traditional writing, titles of movies, books and songs are often off-set with italics or punctuation, but this is not possible in a search query.
With this in mind, you can understand how disambiguation of complex queries and entities becomes more important in voice search – especially with a query like ‘I want to watch American Pie.’ Without Entity Understanding, the query might be processed as a request for a recipe. Now, with Mobile-First Indexing, action words like ‘watch’ and ‘play’ are probably being used to help inform the contextual understanding of the query, and trigger specific media oriented results and Entities, even when media titles lend themselves to confusion. Words like ‘I want’ are probably being dropped out of the query entirely.
Alphabet Selection & Google’s Query Understanding
Things get more complex in language-detection when Latin characters are mixed with additional characters – the Cyrillic and Greek alphabets both do this. The Cyrillic alphabet, for example, contains 30 letters that are sometimes Latin characters and sometimes unique to Cyrillic; so in Bulgarian for example (one of about 13 significant world languages that uses the Cyrillic alphabet), native speakers often use a number OR a 2 or 3-letter combination of Latin characters to replace the Cyrillic characters that are missing from the normal Latin keyboard, rather than hunting for the correct Cyrillic character in extra menus.
EX: ‘ш’ in Cyrillic can also be written as the numeral ‘6’ or the letter combination ‘sh’; similarly, the Cyrillic character ‘ч’ can be written as the numeral ‘4’ or the letter combination ‘ch’. As you can see in the chart below, analogous query and searching patterns are also used with the Greek language and alphabet.
The number of potential variations in one keyword can be very high, especially considering the different character replacements can be mixed in one word – using a Latin letter combinations, numerals and Cyrillic characters in the same word. Though that scenario might be rare, it means that the number of ways to write on keyword becomes quite high, which initially made Google’s language-detection efforts in these languages much harder. Over time Google got better at recognizing these spelling and alphabet variations and determining when they represented the same words (probably by using a system similar to ‘stemming’ from the English algorithms).
To illustrate the concept, top possible variations for how sample keyword phrases can be written using different alphabets are outlined below:
| Language Test | Native Alphabet | English Word | Local Translation Variations | Content Type |
|---|---|---|---|---|
| Bulgarian | Cyrillic | Little Red Riding Hood/(Little Red Hood) | Червената Шапчица Chervenata Shapchica 4ervenata 6ap4ica Chervenata Shapchitsa 4ervenata 6ap4itsa |
Fairy Tale |
| Greek | Greek | Chicken Soup with Vegetables | Κοτόσουπα με λαχανικά Κοτοσουπα με λαχανικα Kotósoupa me lachanika Kotosoupa me laxanika |
Recipe |
Since Bulgarian and Greek are less prevalent languages, Google spent less effort in detecting and translating these languages. We wanted to check if Google would accurately detect all of these language with all of the potential character combinations. We picked these languages because there is such a difficulty in language detection, due to the large number of possible alphabets and letter substitutes in play.
As you can see, this is a lot to expect Google to interpret and understand, but they do. These variations seem to be understood as ‘near-exact synonyms’. We can tell this because Google Instant shows us a mix of all variations of the keyword, with different alphabets and letter replacements included in their Instant suggestions, as shown in the example searches below. The example searches below indicate that Google detects language in Google Search by using the Translation API, even in cases when the language and alphabet of the query do not match the official alphabets of the language. Google seems to prioritise local results based on the choice of query alphabet, but this is probably a product of engagement volume with the particular alphabets, rather than intentional design.


From an SEO perspective, it is very important to realize that even though the different character variations are understood as synonyms in Google Instant, Google returns slightly different search results for each of the variations, depending on how the final query is submitted. Even though the Google Instant autocomplete suggests keywords in all different character variations interchangeably, results appear to correlate with search volume and engagement, but also probably include a small amount of keyword understanding from the Translate API. Also, according the Danny Sullivan, Google’s Search Liaison, these predictions are ‘also related to your location and previous searches’.
NOTE: Computers only pass Google their location using a general IP address, but cell phones can pass the more specific and robust GPS coordinates. It is possible that Google’s machine learning algorithms may have unknowingly been skewed; on one side, towards more localization in the search result for queries that use a less localized alphabet (Latin), and on the other side, towards less localization in the search query results that use the more localized Cyrillic alphabet.
If you are interested in testing mobile search results with specific location, language and alphabet choice, the MobileMoxie SERP Test works for queries in all languages and locations around the world (down to the post-code level of specificity – not just ‘city’ or ‘country’ specific queries!) It also provides more than 20 mobile devices comparison pairs.
Language Detection’s Impact on Entity Understanding
Next, to see how variations in alphabets impact Google’s Entity Understanding, we tested a query for a Spanish movie ‘Y Tu Mamá También’ which, translated in English to be, ‘And Your Mother Too’. This is a good test because it is also the name of a Bulgarian hip-hop song, written like this in Bulgarian: ‘И Твойта Майка Също’. The query could be referencing two separate entities, one of which is known broadly around the world in Spanish, the other is more country-specific and when it is searched for in Bulgaria, it should be associated with a different entity (the hip-hop song) that is well known locally in Bulgaria, but not well known around the world.
When the query is submitted in English and Bulgarian/Cyrillic, the results include the Knowledge Graph result for the Spanish movie, as you can see in screenshots below. However, once we switch and begin typing the name of the movie in Bulgarian, using the Latin alphabet, as shown in screenshot 3 on the bottom, Google Instant shows suggestions related to the Spanish movie AND the Bulgarian song. It also begins to offer Google Instant predictions in the Cyrillic alphabet, suggesting that the Latin formatting of the query triggers a larger Entity Understanding that encompass more queries including ones that are submitted using the other alphabets. Once the Bulgarian query is submitted using Latin characters, the results focus exclusively on the local Bulgarian hip-hop song, and do not include the Spanish movie. There is also a Bulgarian movie with the same name, it seems that the Bulgarian movie signals are not yet strong enough to trigger a Knowledge Graph results, but Google clearly understands that the Spanish movie may be an irrelevant result for this query when the Bulgarian language is detected.
This experiment shows that Google not only detects the language even when the query is not in the native alphabet (Cyrillic), but also suggests query options with alphabetically, linguistically and geographically diverse search results when they are unclear about the searcher’s intent. Google clearly does use alphabets and language as a contextual meaning but uses Google Instant for on-the-fly disambiguation. Prioritization of some results over others may not be an intentional organizing principle to discount the official local or native alphabets, but instead, a result triggered by the higher levels of engagement data that is associated with Latin-alphabet queries.

NOTE: Again, if you are interested in testing your brand’s Entity Understanding in different countries and searches around, the MobileMoxie SERP Test is great for this. It provides real search results for mobile queries on a large number of popular phones and works for queries in all languages, alphabets and locations around the world.
Conclusion
Sometimes, the work that Google has to do to surface good results around the world is not appreciated, but Entity-First Indexing forces it to the front of our minds. This is especially true for SEO’s that focus on international audiences and will have to anticipate how and when Google will relate different queries to specific Entities. In this article, we discussed the various APIs that Google uses to detect and understand languages, and provide search results, even in the cases where a large variety of characters could be used interchangeably to mean the same thing.
Our research clearly shows that Google follows a process for language and query identification that is critical to determining how the query will be understood, and what results will surface as a result of it. When queries are submitted to Google in languages that it has a deep, native understanding of, through the Natural Language API, Google will return better results. When queries are submitted and Google detects that they are not part of the Natural Language API, the algorithm and the results it produces are less accurate and more prone to problems, because they are relying more on keyword matching than keyword understanding.
This was the third article in a five-part series about the relationship between Google’s shift to Mobile-First Indexing (Entity-First Indexing) and language. The first two articles in the series focused on how and why Google needed to make this shift. This article focused on practical research that shows how language impacts queries in Google’s algorithm. The next article will continue to outline our research, first focusing on how and why the order of keywords in a query matters, and impacts Google’s ability to understand the query, depending on the language. Then it will delve into more complex linguistic understanding, like Google’s ability to interpret and parse different idioms and location-specific Entities. The final article in the series will talk about how individual personalization, like the languages that are set up on the phone and the physical location of the searcher play into queries, even when there is not a location or mapping intent detected, and how these are related to Entity Understanding and Entity-First Indexing.