The robots.txt file is an often overlooked and sometimes forgotten part of a website and SEO.
But nonetheless, a robots.txt file is an important part of any SEO’s toolset, whether or not you are just starting out in the industry or you are a chiseled SEO veteran.
What is a robots.txt file?
A robots.txt file can be used for for a variety of things, from letting search engines know where to go to locate your sites sitemap to telling them which pages to crawl and not crawl as well as being a great tool for managing your sites crawl budget.
You might be asking yourself “wait a minute, what is crawl budget?” Well crawl budget is what what Google uses to effectively crawl and index your sites pages. As big a Google is, they still only have a limited number of resources available to be able to crawl and index your sites content.
If your site only has a few hundred URLs then Google should be able to easily crawl and index your site’s pages.
However, if your site is big, like an ecommerce site for example and you have thousands of pages with lots of auto-generated URLs, then Google might not crawl all of those pages and you will be missing on lots of potential traffic and visibility.
This is where the importance of prioritizing what, when and how much to crawl becomes important.
Google have stated that “having many low-value-add URLs can negatively affect a site’s crawling and indexing.” This is where having a robots.txt file can help with the factors affecting your sites crawl budget.
You can use the file to help manage your sites crawl budget, by making sure that search engines are spending their time on your site as efficiently (especially if you have a large site) as possible and crawling only the important pages and not wasting time on pages such as login, signup or thank you pages.
Why do you need robots.txt?
Before a robot such as Googlebot, Bingbot, etc. crawls a webpage, it will first check to see if there is in fact a robots.txt file and, if one exists, they will usually follow and respect the directions found within that file.
A robots.txt file can be a powerful tool in any SEO’s arsenal as it’s a great way to control how search engine crawlers/bots access certain areas of your site. Keep in mind that you need to be sure you understand how the robots.txt file works or you will find yourself accidentally disallowing Googlebot or any other bot from crawling your entire site and not having it be found in the search results!
But when done properly you can control such things as:
- Blocking access to entire sections of your site (dev and staging environment etc.)
- Keeping your sites internal search results pages from being crawled, indexed or showing up in search results.
- Specifying the location of your sitemap or sitemaps
- Optimizing crawl budget by blocking access to low value pages (login, thank you, shopping carts etc..)
- Preventing certain files on your website (images, PDFs, etc.) from being indexed
Robots.txt Examples
Below are a few examples of how you can use the robots.txt file on your own site.
Allowing all web crawlers/robots access to all your sites content:
User-agent: * Disallow:
Blocking all web crawlers/bots from all your sites content:
User-agent: * Disallow: /
You can see how easy it is to make a mistake when creating your sites robots.txt as the difference from blocking your entire site from being seen is a simple forward slash in the disallow directive (Disallow: /).
Blocking a specific web crawlers/bots from a specific folder:
User-agent: Googlebot Disallow: /
Blocking a web crawlers/bots from a specific page on your site:
User-agent: Disallow: /thankyou.html
Exclude all robots from part of the server:
User-agent: * Disallow: /cgi-bin/ Disallow: /tmp/ Disallow: /junk/
This is example of what the robots.txt file on the theverge.com’s website looks like:
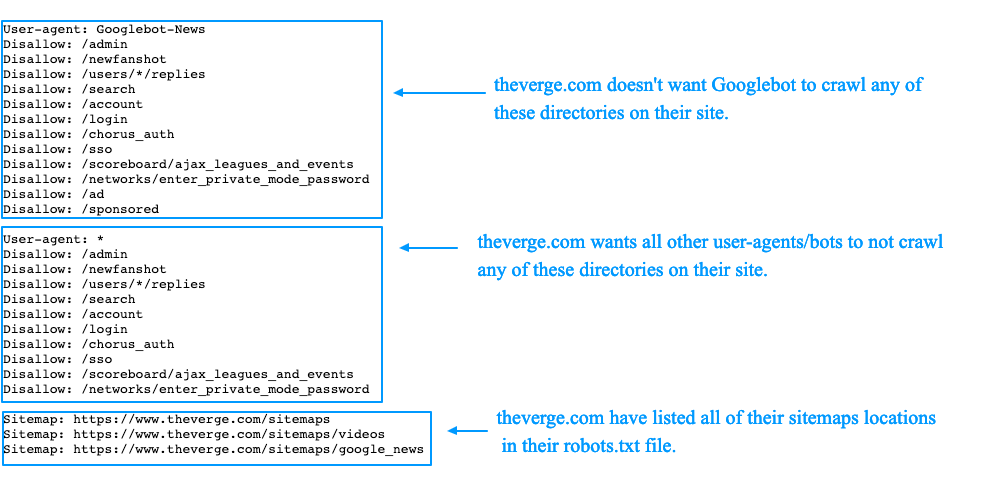
The example file can be viewed here: www.theverge.com/robots.txt
You can see how The Verge use their robots.txt file to specifically call out Google’s news bot “Googlebot-News” to make sure that it doesn’t crawl those directories on the site.
It’s important to remember that if you want to make sure that a bot doesn’t crawl certain pages or directories on your site, that you call out those pages and or directories in the in “Disallow” declarations in your robots.txt file, like in the above examples.
You can review how Google handles the robots.txt file in their robots.txt specifications guide, Google has a current maximum file size limit for the robots.txt file, the maximum size for Google is set at 500KB, so it’s important to be mindful of the size of your sites robots.txt file.
How to create a robots.txt file
Creating a robots.txt file for your site is a fairly simple process, but it’s also easy to make a mistake. Don’t let that discourage you from creating or modifying a robots file for your site. This article from Google walks you through the robots.txt file creation process and should help you get comfortable creating your very own robots.txt file.
Once you are comfortable with creating or modify your site’s robots file, Google has another great article that explains how to test your sites robots.txt file to see if it is setup correctly.
Checking if you have a robots.txt file
If you are new to the robots.txt file or are not sure if your site even has one, you can do a quick check to see. All you need to do to check is go to your sites root domain and then add /robots.txt to the end of the URL. Example: www.yoursite.com/robots.txt
If nothing shows up, then you do not have a robots.txt file for you site. Now would be the perfect time to jump in and test out creating one for your site.
Best Practices:
- Make sure all important pages are crawlable, and content that won’t provide any real value if found in search are blocked.
- Don’t block your sites JavaScript and CSS files
- Always do a quick check of your file to make sure nothing has changed by accident
- Proper capitalization of directory, subdirectory and file names
- Place the robots.txt file in your websites root directory for it to be found
- Robots.txt file is case sensitive, the file must be named “robots.txt” (no other variations)
- Don’t use the robots.txt file to hide private user information as it will still be visible
- Add your sitemaps location to your robots.txt file.
- Make sure that you are not blocking any content or sections of your website you want crawled.
Things to keep in mind:
If you have a subdomain or multiple subdomains on your site, then you you will need to have a robots.txt file on each subdomain as well as on the main root domain. This would look something like this store.yoursite.com/robots.txt and yoursite.com/robots.txt.
Like mentioned above in the “best practices section” it’s important to remember not to use the robots.txt file to prevent sensitive data, such as private user information from being crawled and appearing in the search results.
The reason for this, is that it’s possible that other pages might be linking to that information and if there’s a direct link back it will bypass the robots.txt rules and that content may still get indexed. If you need to block your pages from truly being indexed in the search results, use should use different method like adding password protection or by adding a noindex meta tag to those pages. Google can not login to a password protected site/page, so they will not be able to crawl or index those pages.
Conclusion
While you might be a little nervous if you have never worked on robots.txt file before, rest assured it is fairly simple to use and set up. Once you get comfortable with the ins and outs of the robots file, you’ll be able to enhance your site’s SEO as well as help your site’s visitors and search engine bots.
By setting up your robots.txt file the right way, you will be helping search engine bots spend their crawl budgets wisely and help ensure that they aren’t wasting their time and resources crawling pages that don’t need to be crawled. This will help them in organizing and displaying your sites content in the SERPs in the best way possible, which in turn means you’ll have more visibility.
Keep in mind that it doesn’t necessarily take a whole lot of time and effort to setup your robots.txt file. For the most part, it’s a one-time setup, that you can then make little tweaks and changes to help better sculpt your site.
I hope the practices, tips and suggestions described in this article will help give you the confidence to go out and create/tweak your sites robots.txt file and at the same time help guide you smoothly through the process.
The post Robots.txt best practice guide + examples appeared first on Search Engine Watch.