Some search engine optimization professionals and developers have concluded in the last couple of years that Google can crawl JavaScript. Unfortunately, that’s not always the case. Sites using Angular (the open source app builder) and certain JavaScript techniques pay the price.
Ecommerce sites typically use some form of modern JavaScript — AJAX, lazy loading, single-page applications, Angular. I’ll refer to these as “complex” JavaScript for this article.
Knowing how to talk to your developers about these topics and their impact is critical to search engine optimization. While cutting off innovation on your site isn’t an option — and complex JavaScript is an essential element to website innovation — understanding the risks to SEO is important.
In 2015, Google released a statement that read, “We are generally able to render and understand your web pages like modern browsers.” Some felt confident after that apparent blanket assurance that Google didn’t need any special handholding to index complex JavaScript-based content. But technology is evolving. What existed in 2015 is much different than today.
At Google’s annual I/O developer conference earlier this month, two Google representatives — John Mueller, webmaster trends analyst, and Tom Greenaway, partner developer advocate for indexing of progressive web applications — spoke about search-friendly JavaScript-powered websites.
Some of what they said has been discussed in technical forums. But the subject can be hard for marketers to follow. In the article, I’ll address in less technical terms the primary issues surrounding the indexing of complex JavaScript.
Client vs. Server
Whether a web page is rendered server-side or the client-side matters to SEO. In fact, it’s one of the central issues. Server-side rendering is how content was traditionally delivered — you click on a link, the browser requests the page from the web server, and the server crunches the code to deliver the page in full to your browser.
As pages have become more complex, that work is increasingly done by the browser — the client side. Client-side rendering saves server resources, leading to faster web pages. Unfortunately, it can hurt search-engine friendliness.
Googlebot and other search engine crawlers don’t have the resources to render and digest every page as they crawl it. Web servers used to do that and deliver the result to the search engines for easy indexing. But with client-side rendering, the bots have to do much more work. They save the more complex JavaScript to render later as resources allow.
Slow Indexing
This crawl-now-render-later phenomenon creates a delay. “If you have a large dynamic website, then the new content might take a while to be indexed,” according to Mueller.
Let’s say you’re launching a new line of products. You need those products to be indexed as quickly as possible, to drive revenue. If your site relies on client-side rendering or complex forms of JavaScript, it “might take a while.”
Even more challenging, say your site is migrating to Angular or a JavaScript framework. When you relaunch the site, the source code will change to the extent that it contains no textual content outside of the title tag and meta description, and no links to crawl until Google gets around to rendering it, which “might take a while.”
That means a delay of days or weeks — depending on how much authority your site has — in which the search engines see no content or links on your site. At that point, your rankings and organic search traffic drop, unless you’re using some form of prerendering technology.
Crawlable Links
To complicate matters further, JavaScript supports multiple ways of creating links, including spans and onclicks.
Internal links are critical for search engines to discover pages and assign authority. But unless those pages contain both an anchor tag and an href attribute, Google will not consider it a link and will not crawl it.
Span tags do not create crawlable links. Anchor tags with onclick attributes but no href attributes do not create crawlable links.
“At Google, we only analyze one thing: anchor tags with href attributes and that’s it,” according to Greenaway.
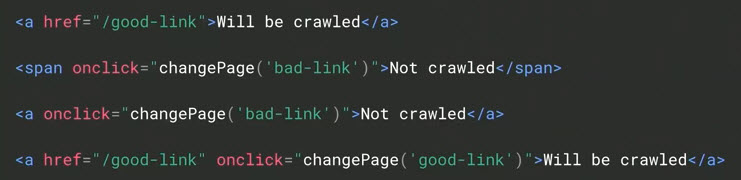
To Google, an href is a crawlable link. A onclick is not.
Newer JavaScript
Googlebot is several years behind with the JavaScript it supports. The bot is based on Chrome 41, which was released in March 2015 when an older standard for JavaScript (ECMAScript 5, or ES5) was in use.
JavaScript’s current standard version, ES6, was released in June 2015, three months after Chrome 41. That is important. It means that Googlebot does not support the most modern functions and capabilities of JavaScript.
“Googlebot is currently using a somewhat older browser to render pages,” according to Mueller. “The most visible implication for developers is that newer JavaScript versions and coding conventions like arrow functions aren’t supported by Googlebot.”
Mueller stated that if you rely on modern JavaScript functionality — for example, if you have any libraries that can’t be transpiled back to ES5 — use alternate means like graceful degradation to help Google and other search engines index and rank your site.
In short, modern, complex ecommerce sites should assume that search engines will have trouble indexing.
Organic search is the primary source of customer acquisition for most online businesses. But it’s vulnerable. A website is one technical change away from shutting off the flow — i.e., it “might take a while.” The stakes are too high.
Send the video of Mueller and Greenaway’s presentation to your SEO and developer teams. Have a viewing party with pizza and beverages. While it’s likely they know that there are SEO risks associated with JavaScript, hearing it from Google directly could prevent a catastrophe.