



Many people are more afraid of duplicate content than they are of spammy links.
There are so many myths around duplicate content that people actually think it causes a penalty and that their pages will compete against each other and hurt their website. I see forum posts, Reddit threads, technical audits, tools, and even SEO news websites publishing articles that show people clearly don’t understand how Google treats duplicate content.
Google tried to kill off the myths around duplicate content years ago. Susan Moska posted on the Google Webmaster blog in 2008:
Let’s put this to bed once and for all, folks: There’s no such thing as a “duplicate content penalty.” At least, not in the way most people mean when they say that.
You can help your fellow webmasters by not perpetuating the myth of duplicate content penalties!
Sorry we failed you, Susan.
What is duplicate content?
Duplicate content generally refers to substantive blocks of content within or across domains that either completely match other content or are appreciably similar. Mostly, this is not deceptive in origin.
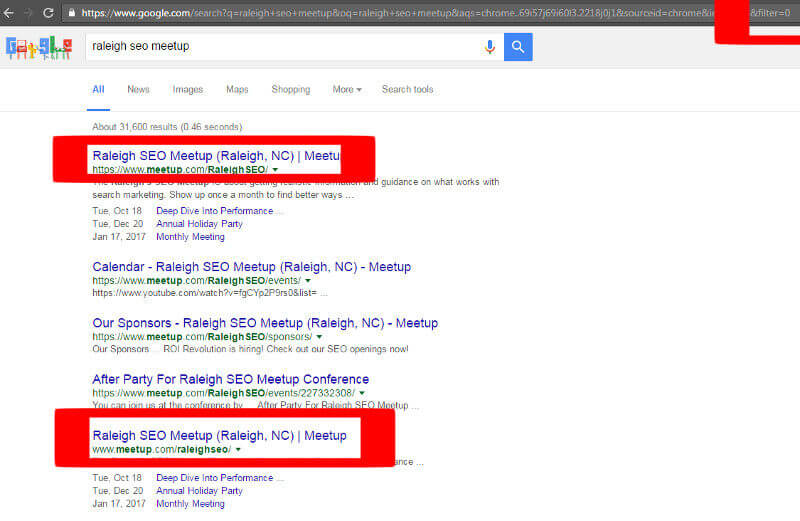
People mistake duplicate content for a penalty because of how Google handles it. Really, the duplicates are just being filtered in the search results. You can see this for yourself by adding &filter=0 to the end of the URL and removing the filtering.
Adding &filter=0 to the end of the page URL on a search for “raleigh seo meetup” will show me the exact same page twice. I’m not saying Meetup has done a good job with this, since they actually indicate the two versions (HTTP and HTTPS in this case) are both correct in their use of canonical tags, but I think it does show that the exact same page (or similar pages) are actually indexed, and only the most relevant is being shown. It’s not that the page is necessarily competing or doing any harm to the website itself.

How much of the web is duplicated?
According to Matt Cutts, 25 to 30 percent of the web is duplicate content. A recent study by Raven Tools based on data from their site auditor tool found a similar result, in that 29 percent of pages had duplicate content.
What are Google’s thoughts on duplicate content?
Many great posts have been published by Googlers. I’m going to give you a summary of the best parts, but I recommend reading over the posts as well.
- Duplicate content doesn’t cause your site to be penalized.
- Googlers know that users want diversity in the search results and not the same article over and over, so they choose to consolidate and show only one version.
- Google actually designed algorithms to prevent duplicate content from affecting webmasters. These algorithms group the various versions into a cluster, the “best” URL in the cluster is displayed, and they actually consolidate various signals (such as links) from pages within that cluster to the one being shown. They even went as far as saying, “If you don’t want to worry about sorting through duplication on your site, you can let us worry about it instead.”
- Duplicate content is not grounds for action unless its intent is to manipulate search results.
- About the worst thing that can happen from this filtering is that a less desirable version of the page will be shown in search results.
- Google tries to determine the original source of the content and display that one.
- If someone is duplicating your content without permission, you can request to have it removed by filing a request under the Digital Millennium Copyright Act.
- Do not block access to duplicate content. If they can’t crawl all the versions, they can’t consolidate the signals.
Sources:
Deftly dealing with duplicate content
Duplicate content due to scrapers
Google, duplicate content caused by URL parameters, and you
Duplicate content summit at SMX Advanced
Learn the impact of duplicate URLs
Duplicate content (Search Console Help)
Causes of duplicate content
- HTTP and HTTPS
- www and non-www
- Parameters and faceted navigation
- Session IDs
- Trailing slashes
- Index pages
- Alternate page versions such as m. or AMP pages or print
- Dev/hosting environments
- Pagination
- Scrapers
- Country/language versions
Solutions to duplicate content
The solution will depend on the particular situation:
- Do nothing and hope Google gets it right. While I wouldn’t recommend this course of action, you may have read previously that Google will cluster the pages and consolidate the signals, effectively handling duplicate content issues for you.
- Canonical tags. These tags are used to consolidate signals and pick your preferred version. It’s a pet peeve of mine when a website has canonical tags set correctly and I see an audit that says there are duplicate content issues. It’s not an issue at that point, so don’t say that it is.
- 301 redirects. This would prevent pages from even having most duplication issues by preventing some alternate versions from being displayed.
- Tell Google how to handle URL parameters. Setting these up tells Google what the parameters are actually doing instead of letting them try to figure it out.
- Rel=”alternate”. Used to consolidate alternate versions of a page, such as mobile or various country/language pages. With country/language in particular, hreflang is used to show the correct country/language page in the search results. A few months ago, Google’s John Mueller, answering a question in the Webmaster Hangout, said that fixing hreflang wouldn’t increase rankings but would only help the correct version show. This is likely because Google has already identified the alternate versions and consolidated the signals for the different pages.
- Rel=”prev” and rel=”next”. Used for pagination.
- Follow syndication best practices.
TL;DR
There are some things that could actually cause problems, such as scraping/spam, but for the most part, problems would be caused by the websites themselves. Don’t disallow in robots.txt, don’t nofollow, don’t noindex, don’t canonical from pages targeting longer-tail to overview-type pages, but do use the signals mentioned above for your particular issues to indicate how you want the content to be treated. Check out Google’s help section on duplicate content.
Myths about duplicate content penalties need to die. Audits, tools and misunderstandings need correct information, or this myth might be around for another 10 years. There are plenty of ways to consolidate signals across multiple pages, and even if you don’t use them, Google will try to consolidate the signals for you.
Opinions expressed in this article are those of the guest author and not necessarily Search Engine Land. Staff authors are listed here.
About The Author



Patrick Stox is an SEO Specialist for IBM and an organizer for the Raleigh SEO Meetup, the most successful SEO Meetup in the US.